Rétro-ingénierie de NativeImage
La restauration et la protection du code Java est un sujet ancien et souvent débattu. En raison du format bytecode utilisé pour stocker les fichiers Class Java, qui contient beaucoup de méta-informations, il peut être facilement restauré en son code original. Afin de protéger le code Java, l'industrie a adopté de nombreuses méthodes, telles que l'obfuscation, le chiffrement du bytecode, la protection JNI, etc. Cependant, quelle que soit la méthode utilisée, il existe toujours des moyens de le craquer.
La compilation binaire a toujours été considérée comme une méthode relativement efficace de protection du code. La compilation binaire de Java est supportée sous le nom de technologie AOT (Ahead of Time), ce qui signifie pré-compilation.
Cependant, en raison de la nature dynamique du langage Java, la compilation binaire doit gérer des problèmes tels que la réflexion, le proxy dynamique, le chargement JNI, etc., ce qui pose de nombreuses difficultés. Par conséquent, pendant longtemps, il n'existait pas d'outil mature, fiable et adaptable pour la compilation AOT en Java pouvant être largement appliqué en environnement de production. (Il existait autrefois un outil appelé Excelsior JET, mais il semble avoir été abandonné maintenant.)
En mai 2019, Oracle a publié GraalVM 19.0, une machine virtuelle supportant plusieurs langages, qui était sa première version prête pour la production. GraalVM fournit un outil NativeImage qui peut réaliser la compilation AOT des programmes Java. Après plusieurs années de développement, NativeImage est maintenant très mature, et SpringBoot 3.0 peut l'utiliser pour compiler l'ensemble du projet SpringBoot en un fichier exécutable. Le fichier compilé a une vitesse de démarrage rapide, une faible utilisation mémoire et d'excellentes performances.
Alors, pour les programmes Java qui sont entrés dans l'ère de la compilation binaire, leur code est-il toujours aussi facilement réversible que dans l'ère du bytecode ? Quelles sont les caractéristiques des fichiers binaires compilés par NativeImage, et l'intensité de la compilation binaire est-elle suffisante pour protéger le code important ?
Pour explorer ces questions, nous avons récemment développé un outil d'analyse NativeImage, qui a atteint un certain degré d'effet de rétro-ingénierie.
Projet
https://github.com/vlinx-io/NativeImageAnalyzer
Générer un NativeImage
Tout d'abord, nous devons générer un NativeImage. NativeImage provient de GraalVM. Pour télécharger GraalVM, rendez-vous sur https://www.graalvm.org/ et téléchargez la version pour Java 17. Après le téléchargement, configurez la variable d'environnement. Comme GraalVM contient un JDK, vous pouvez directement l'utiliser pour exécuter la commande java.
Ajoutez $GRAALVM_HOME/bin à la variable d'environnement, puis exécutez la commande suivante pour installer l'outil native-image
gu install native-image
Un programme Java simple
Écrivez un programme Java simple, par exemple :
public class Hello {
public static void main(String[] args){
System.out.println("Hello World!");
}
}
Compilez et exécutez le programme Java ci-dessus :
javac Hello.java
java -cp . Hello
Vous obtiendrez la sortie suivante :
Hello World!
Préparation de l'environnement de compilation
Si vous êtes un utilisateur Windows, vous devez d'abord installer Visual Studio. Si vous êtes un utilisateur Linux ou macOS, vous devez installer au préalable des outils comme gcc et clang.
Pour les utilisateurs Windows, vous devez configurer la variable d'environnement pour Visual Studio avant d'exécuter la commande native-image. Vous pouvez la configurer avec la commande suivante :
"C:\Program Files (x86)\Microsoft Visual Studio\2017\Community\VC\Auxiliary\Build\vcvars64.bat"
Si le chemin d'installation et la version de Visual Studio sont différents, veuillez ajuster les informations de chemin en conséquence.
Compiler avec native-image
Utilisez maintenant la commande native-image pour compiler le programme Java ci-dessus en fichier binaire. Le format de la commande native-image est le même que celui de la commande java, elle possède également les paramètres -cp, -jar. Comment utiliser la commande java pour exécuter le programme, utilisez la même méthode pour la compilation binaire, remplacez simplement la commande java par native-image. Exécutez la commande suivante
native-image -cp . Hello
Après une période de compilation, qui peut consommer davantage de CPU et de mémoire, vous obtenez un fichier binaire compilé. Le nom du fichier de sortie par défaut est le nom de la classe principale en minuscules, soit « hello » dans ce cas. Sous Windows, ce sera « hello.exe ». Utilisez la commande « file » pour vérifier le type de ce fichier, vous pouvez voir qu'il s'agit bien d'un fichier binaire.
file hello
hello: Mach-O 64-bit executable x86_64
Exécutez ce fichier, et sa sortie sera identique à celle obtenue précédemment avec java -cp . Hello
Hello World!
Analyser NativeImage
Analyse avec IDA
Utilisez IDA pour ouvrir le fichier hello compilé à l'étape précédente, cliquez sur Exports pour voir la table des symboles, vous pouvez voir le symbole svm_code_section, et son adresse est l'adresse d'entrée de la fonction Main Java.
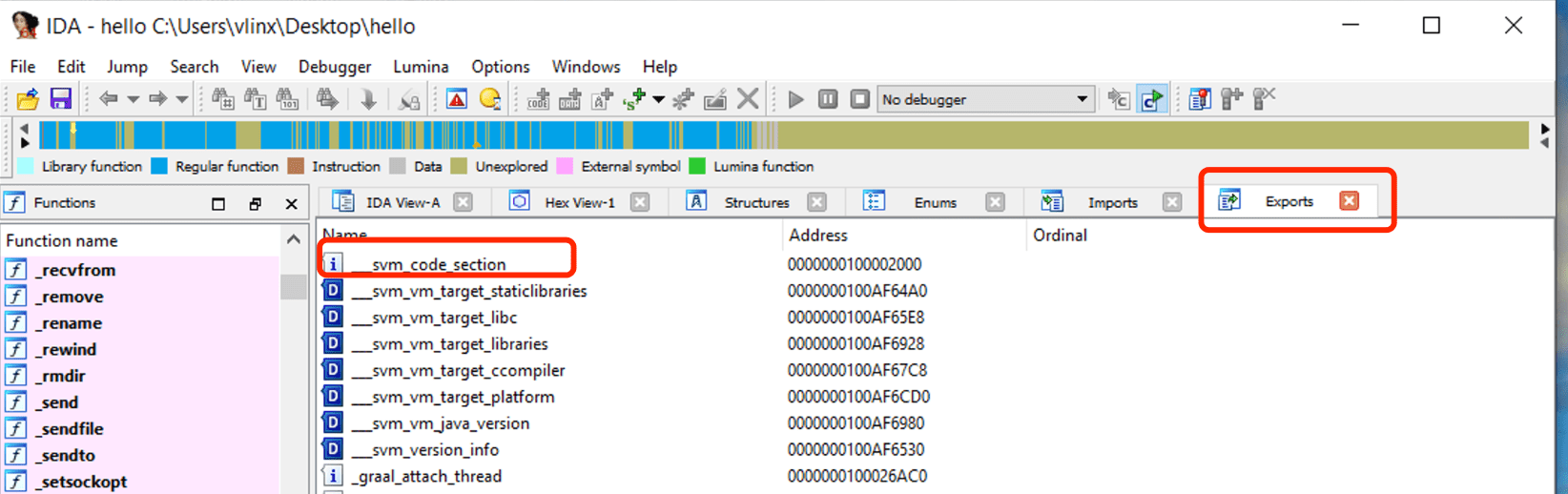
Naviguez vers cette adresse pour voir le code assembleur
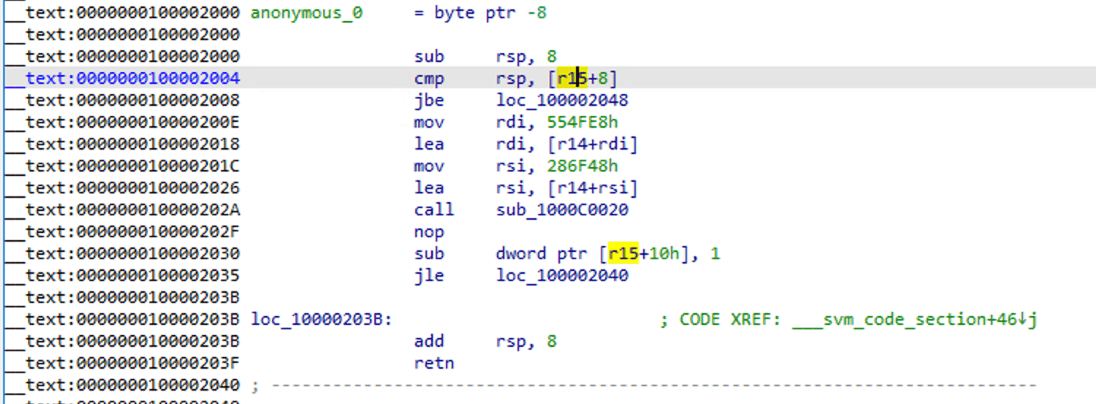
Vous pouvez voir qu'il est devenu une fonction assembleur standard, utilisez F5 pour décompiler
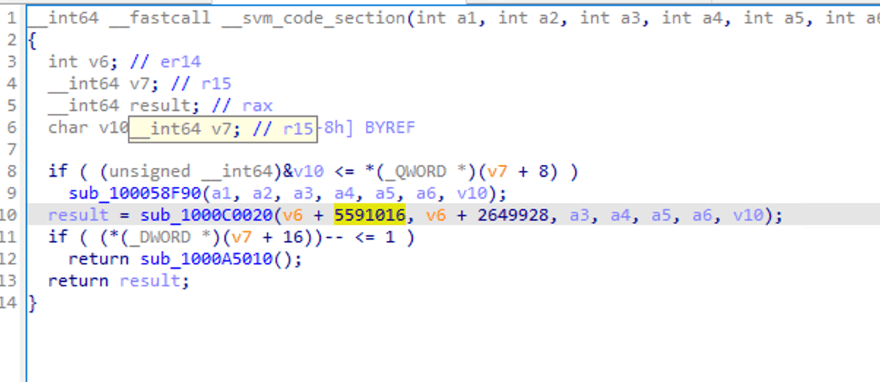
On peut voir quelques appels de fonctions et certains paramètres passés, mais il n'est pas facile de voir la logique.
Lorsque nous double-cliquons sur sub_1000C0020, regardons à l'intérieur de l'appel de fonction. IDA indique un échec d'analyse.
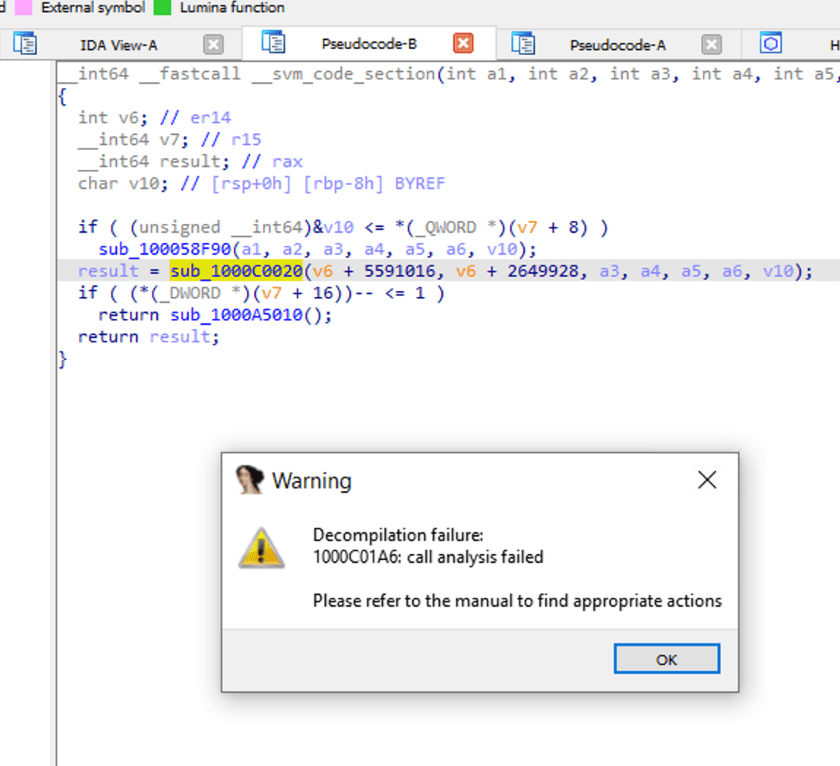
Logique de décompilation de NativeImage
Parce que la compilation de NativeImage est basée sur la compilation JVM, elle peut aussi être comprise comme enveloppant le code binaire avec une couche de protection VM. Par conséquent, des outils comme IDA sont incapables de la rétro-ingéniérer correctement en l'absence d'informations correspondantes et de mesures de traitement ciblées.
Cependant, quel que soit le format, que ce soit en bytecode ou en forme binaire, certains éléments de base de l'exécution JVM sont forcément présents, tels que les informations de classe, les informations de champ, l'invocation de fonctions et le passage de paramètres. Sur la base de cette réflexion, l'outil d'analyse que j'ai développé peut atteindre un certain niveau de restauration et, avec des améliorations supplémentaires, avoir la capacité d'atteindre un haut niveau de précision de restauration.
Analyse avec NativeImageAnalyzer
Visitez https://github.com/vlinx-io/NativeImageAnalyzer pour télécharger NativeImageAnalyzer
Exécutez la commande suivante pour l'analyse inverse, analysant actuellement uniquement la fonction Main de la classe principale
native-image-analyzer hello
La sortie est la suivante
java.io.PrintStream.writeln(java.io.PrintStream@0x554fe8, "Hello World!", rcx)
return
Revoyons le code original.
public static void main(String[] args){
System.out.println("Hello World!");
}
Regardons maintenant la définition de System.out.
public static final PrintStream out = null;
On peut voir que la variable 'out' de la classe System est une variable de type PrintStream, et c'est une variable statique. Lors de la compilation, NativeImage compile directement une instance de cette classe dans une zone appelée Heap, et le code binaire récupère directement cette instance depuis la zone Heap pour l'invocation. Regardons le code original après restauration.
java.io.PrintStream.writeln(java.io.PrintStream@0x554fe8, "Hello World!", rcx)
return
Ce java.io.PrintStream@0x554fe8 est simplement l'instance de java.io.PrintStream lue depuis la zone Heap, située à l'adresse mémoire 0x554fe8.
Examinons maintenant la définition de la fonction java.io.PrintStream.writeln
private void writeln(String s) {
......
}
Ici, on peut voir qu'il y a un argument String dans la fonction writeln, mais dans le code restauré, pourquoi trois arguments sont-ils passés ? Premièrement, writeln est une méthode d'instance de classe qui cache un seul this, la variable pointe vers l'appelant, qui est le premier paramètre passé, java.io.PrintStream@0x554fe8. Quant au troisième paramètre rcx, c'est parce que lors de l'analyse du code assembleur, il a été déterminé que cette fonction était appelée avec trois paramètres. Cependant, en examinant la définition, nous savons que cette fonction n'appelle en réalité que deux paramètres. C'est aussi un domaine qui nécessite des améliorations futures pour cet outil.
Un programme plus complexe
Nous allons maintenant analyser un programme plus complexe, par exemple le calcul d'une suite de Fibonacci, avec le code suivant
class Fibonacci {
public static void main(String[] args) {
int count = Integer.parseInt(args[0]);
int n1 = 0, n2 = 1, n3;
System.out.print(n1 + " " + n2);
for (int i = 2; i < count; ++i){
n3 = n1 + n2;
System.out.print(" " + n3);
n1 = n2;
n2 = n3;
}
System.out.println();
}
}
Compilez et exécutez
javac Fibonacci.java
native-image -cp . Fibonacci
./fibonacci 10
0 1 1 2 3 5 8 13 21 34
Le code obtenu après restauration avec NativeImageAnalyzer est le suivant
rdi = rdi[0]
ret_0 = java.lang.Integer.parseInt(rdi, 10)
sp_0x44 = ret_0
ret_1 = java.lang.StringConcatHelper.mix(1, 1)
ret_2 = java.lang.StringConcatHelper.mix(ret_1, 0)
sp_0x20 = java.io.PrintStream@0x554fe8
sp_0x18 = Class{[B}_1
tlab_0 = Class{[B}_1
tlab_0.length = ret_2<<ret_2>>32
sp_0x10 = tlab_0
ret_28 = ?java.lang.StringConcatHelper.prepend(tlab_0, " ", ret_2)
ret_29 = java.lang.StringConcatHelper.prepend(ret_28, sp_0x10, 0)
ret_30 = ?java.lang.StringConcatHelper.newString(sp_0x10, ret_29)
java.io.PrintStream.write(sp_0x20, ret_30)
if(sp_0x44>=3)
{
ret_7 = java.lang.StringConcatHelper.mix(1, 1)
tlab_1 = sp_0x18
tlab_1.length = ret_7<<ret_7>>32
sp_0x10 = " "
sp_0x8 = tlab_1
ret_22 = ?java.lang.StringConcatHelper.prepend(tlab_1, " ", ret_7)
ret_23 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_22)
rsi = ret_23
java.io.PrintStream.write(sp_0x20, ret_23)
rdi = 1
rdx = 1
rcx = 3
while(true)
{
if(sp_0x44<=rcx)
{
break
}
else
{
sp_0x34 = rcx
rdi = rdi+rdx
r9 = rdi
sp_0x30 = rdx
sp_0x2c = r9
ret_11 = java.lang.StringConcatHelper.mix(1, r9)
tlab_2 = sp_0x18
tlab_2.length = ret_11<<ret_11>>32
sp_0x8 = tlab_2
ret_17 = ?java.lang.StringConcatHelper.prepend(tlab_2, sp_0x10, ret_11)
ret_18 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_17)
rsi = ret_18
java.io.PrintStream.write(sp_0x20, ret_18)
rcx = sp_0x34+1
rdi = sp_0x30
rdx = sp_0x2c
}
}
}
java.io.PrintStream.newLine(sp_0x20, rsi)
return
Comparons le code restauré avec le code original.
rdi = rdi[0]
ret_0 = java.lang.Integer.parseInt(rdi, 10)
sp_0x44 = ret_0
Ceci correspond à
int count = Integer.parseInt(args[0]);
rdi est le registre utilisé pour passer le premier argument d'une fonction. Sous Windows, rdi = rdi[0] correspond à args[0]. Ensuite, on appelle java.lang.Integer.parseInt pour analyser et obtenir une valeur int, puis on assigne la valeur de retour à une variable de pile sp_0x44.
int n1 = 0, n2 = 1, n3;
System.out.print(n1 + " " + n2);
Correspond à
ret_1 = java.lang.StringConcatHelper.mix(1, 1)
ret_2 = java.lang.StringConcatHelper.mix(ret_1, 0)
sp_0x20 = java.io.PrintStream@0x554fe8
sp_0x18 = Class{[B}_1
tlab_0 = Class{[B}_1
tlab_0.length = ret_2<<ret_2>>32
sp_0x10 = tlab_0
ret_28 = ?java.lang.StringConcatHelper.prepend(tlab_0, " ", ret_2)
ret_29 = java.lang.StringConcatHelper.prepend(ret_28, sp_0x10, 0)
ret_30 = ?java.lang.StringConcatHelper.newString(sp_0x10, ret_29)
java.io.PrintStream.write(sp_0x20, ret_30)
Dans notre code Java, la simple opération de concaténation de chaînes est en réalité convertie en trois appels de fonctions : StringConcatHelper.mix, StringConcatHelper.prepend et StringConcatHelper.newString. Parmi eux, StringConcatHelper.mix calcule la longueur de la chaîne concaténée, StringConcatHelper.prepend combine les tableaux byte[] qui portent le contenu spécifique de la chaîne ensemble, et StringConcatHelper.newString génère un nouvel objet String à partir du tableau byte[].
Dans le code ci-dessus, nous voyons deux types de noms de variables, sp_0x18 et tlab_0. Les variables commençant par sp_ indiquent des variables allouées sur la pile, tandis que les variables commençant par tlab_ indiquent des variables allouées sur les Thread Local Allocation Buffers. Ceci n'est qu'une explication de l'origine de ces deux types de noms de variables. Dans le code restauré, il n'y a pas de distinction entre ces deux types de variables. Pour les informations relatives aux Thread Local Allocation Buffers, veuillez effectuer vos propres recherches.
Ici, nous assignons tlab_0 à Class{[B}_1. La signification de Class{[B}_1 est une instance du type byte[]. [B représente le descripteur Java pour byte[], _1 indique qu'il s'agit de la première variable de ce type. S'il y a des variables ultérieures définies pour le type correspondant, l'index augmentera en conséquence, comme Class{[B]}_2, Class{[B]}_3, etc. La même représentation s'applique aux autres types, comme Class{java.lang.String}_1, Class{java.util.HashMap}_2, etc.
La logique du code ci-dessus explique simplement la création d'une instance de tableau byte[] et son assignation à tlab0. La longueur du tableau est ret_2 << ret_2 >> 32. La raison pour laquelle la longueur du tableau est ret_2 << ret_2 >> 32 est que lors du calcul de la longueur d'un String, il faut convertir la longueur du tableau en fonction de l'encodage. Vous pouvez consulter le code pertinent dans java.lang.String.java. Ensuite, la fonction prepend combine 0, 1 et les espaces dans tlab0, puis génère un nouvel objet String ret_30 à partir de tlab_0 et le passe à la fonction java.io.PrintStream.write pour l'affichage. En réalité, les paramètres restaurés par la fonction prepend ne sont pas très précis et leurs positions sont également incorrectes. C'est un domaine qui nécessite des améliorations ultérieures.
Après la conversion des deux lignes de code Java en logique d'exécution réelle, c'est encore assez complexe. À l'avenir, cela pourra être simplifié en analysant et en intégrant sur la base du code actuellement restauré.
Continuons
for (int i = 2; i < count; ++i){
n3 = n1 + n2;
System.out.print(" " + n3);
n1 = n2;
n2 = n3;
}
System.out.println();
Correspond à
if(sp_0x44>=3)
{
ret_7 = java.lang.StringConcatHelper.mix(1, 1)
tlab_1 = sp_0x18
tlab_1.length = ret_7<<ret_7>>32
sp_0x10 = " "
sp_0x8 = tlab_1
ret_22 = ?java.lang.StringConcatHelper.prepend(tlab_1, " ", ret_7)
ret_23 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_22)
rsi = ret_23
java.io.PrintStream.write(sp_0x20, ret_23)
rdi = 1
rdx = 1
rcx = 3
while(true)
{
if(sp_0x44<=rcx)
{
break
}
else
{
sp_0x34 = rcx
rdi = rdi+rdx
r9 = rdi
sp_0x30 = rdx
sp_0x2c = r9
ret_11 = java.lang.StringConcatHelper.mix(1, r9)
tlab_2 = sp_0x18
tlab_2.length = ret_11<<ret_11>>32
sp_0x8 = tlab_2
ret_17 = ?java.lang.StringConcatHelper.prepend(tlab_2, sp_0x10, ret_11)
ret_18 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_17)
rsi = ret_18
java.io.PrintStream.write(sp_0x20, ret_18)
rcx = sp_0x34+1
rdi = sp_0x30
rdx = sp_0x2c
}
}
}
java.io.PrintStream.newLine(sp_0x20, rsi)
return
sp_0x44 est le paramètre que nous avons entré dans le programme, qui correspond à count. La boucle for dans le code Java ne sera exécutée que si count >= 3. Ici, la boucle for est transformée en boucle while, ayant essentiellement la même sémantique. En dehors de la boucle while, le programme exécute la logique où count=3. Si count <= 3, le programme termine son exécution et n'entrera plus dans la boucle while. Cela peut aussi être une optimisation effectuée par GraalVM lors de la compilation.
Regardons à nouveau la condition de sortie de la boucle.
if(sp_0x44<=rcx)
{
break
}
Ceci correspond à
i < count
En même temps, rcx s'accumule également à chaque itération.
sp_0x34 = rcx
rcx = sp_0x34+1
correspond à
++i
Ensuite, regardons comment la logique d'addition des nombres dans le corps de la boucle est reflétée dans le code restauré. Le code original est le suivant :
for(......){
......
n3 = n1 + n2;
n1 = n2;
n2 = n3;
......
}
Le code après restauration est
while(true){
......
rdi = rdi+rdx -> n3 = n1 + n2
r9 = rdi -> r9 = n3
sp_0x30 = rdx -> sp_0x30 = n2
sp_0x2c = r9 -> sp_0x2c = n3
rdi = sp_0x30 -> n1 = sp_0x30 = n2
rdx = sp_0x2c -> n2 = sp_0x2c = n3
......
}
Le reste du code dans le corps de la boucle effectue des opérations de concaténation de chaînes et d'affichage comme auparavant. Le code restauré reflète essentiellement la logique d'exécution du code original.
Améliorations nécessaires
Actuellement, cet outil est capable de restaurer partiellement le flux de contrôle du programme, de réaliser un certain niveau d'analyse du flux de données et de restauration des noms de fonctions. Pour devenir un outil complet et utilisable, il doit encore accomplir les objectifs suivants :
Restauration plus précise des noms de fonctions, des paramètres de fonctions et des valeurs de retour de fonctions
Restauration précise des informations d'objets et de champs
Inférence plus précise des expressions et des types d'objets
Intégration et simplification des instructions
Réflexions sur la protection binaire
L'objectif de ce projet est d'explorer la faisabilité de la rétro-ingénierie de NativeImage. Sur la base des résultats actuels, il est faisable de rétro-ingéniérer NativeImage, ce qui pose également des défis plus élevés pour la protection du code. De nombreux développeurs pensent que compiler les logiciels en binaires peut garantir la sécurité, négligeant la protection du code binaire. Pour les logiciels écrits en C/C++, de nombreux outils tels qu'IDA ont déjà d'excellents effets de rétro-ingénierie, exposant parfois même plus d'informations que les programmes Java. J'ai même vu certains logiciels distribués en forme binaire sans supprimer les informations de symboles des noms de fonctions, ce qui équivaut à fonctionner sans aucune protection.
Tout code est composé de logique. Tant qu'il contient de la logique, il est possible de restaurer sa logique par des moyens de rétro-ingénierie. La seule différence réside dans la difficulté de la restauration. La protection du code vise à maximiser la difficulté d'une telle restauration.