Ingegneria inversa di NativeImage
Il ripristino e la protezione del codice Java sono un problema antico e spesso dibattuto. Grazie al formato bytecode utilizzato per memorizzare i file di classe Java, che contiene numerose meta-informazioni, è possibile ripristinarne facilmente il codice originale. Per proteggere il codice Java, il settore ha adottato numerosi metodi, come l'offuscamento, la crittografia bytecode, la protezione JNI e così via. Tuttavia, indipendentemente dal metodo utilizzato, esistono ancora modi e mezzi per decifrarlo.
La compilazione binaria è sempre stata considerata un metodo relativamente efficace per la protezione del codice. La compilazione binaria di Java è supportata dalla tecnologia AOT (Ahead of Time), ovvero la pre-compilazione.
Tuttavia, a causa della natura dinamica del linguaggio Java, la compilazione binaria deve gestire problematiche come la riflessione, il proxy dinamico, il caricamento JNI, ecc., il che pone numerose difficoltà. Pertanto, per lungo tempo è mancato uno strumento maturo, affidabile e adattabile per la compilazione AOT in Java, che potesse essere ampiamente applicato in ambienti di produzione. (Esisteva uno strumento chiamato Excelsior JET, ma sembra che ora sia stato dismesso.)
Nel maggio 2019, Oracle ha rilasciato GraalVM 19.0, una macchina virtuale con supporto multilingua, la sua prima versione pronta per la produzione. GraalVM fornisce uno strumento NativeImage in grado di eseguire la compilazione AOT di programmi Java. Dopo diversi anni di sviluppo, NativeImage è ora molto maturo e SpringBoot 3.0 può utilizzarlo per compilare l'intero progetto SpringBoot in un file eseguibile. Il file compilato offre un'elevata velocità di avvio, un basso utilizzo di memoria e prestazioni eccellenti.
Quindi, per i programmi Java entrati nell'era della compilazione binaria, il codice è ancora facilmente reversibile come lo era nell'era del bytecode? Quali sono le caratteristiche dei file binari compilati da NativeImage e l'intensità della compilazione binaria è sufficiente a proteggere il codice importante?
Per esplorare queste problematiche, abbiamo recentemente sviluppato uno strumento di analisi NativeImage, che ha ottenuto un certo grado di effetto inverso.
Progetto
https://github.com/vlinx-io/NativeImageAnalyzer
Generazione di NativeImage
Per prima cosa, dobbiamo generare una NativeImage. NativeImage proviene da GraalVM. Per scaricare GraalVM, vai su https://www.graalvm.org/ e scarica la versione per Java 17. Dopo il download, imposta la variabile d'ambiente. Poiché GraalVM contiene un JDK, puoi utilizzarlo direttamente per eseguire il comando java.
Aggiungere $GRAALVM_HOME/bin alla variabile di ambiente, quindi eseguire il seguente comando per installare lo strumento native-image
gu install native-image
Un semplice programma Java
Scrivi un semplice programma Java, ad esempio:
public class Hello {
public static void main(String[] args){
System.out.println("Hello World!");
}
}
Compila ed esegui il programma Java sopra:
javac Hello.java
java -cp . Hello
Otterrai il seguente output:
Hello World!
Preparazione per l'ambiente di compilazione
Se sei un utente Windows, devi prima installare Visual Studio. Se sei un utente Linux o macOS, devi prima installare strumenti come gcc e clang.
Per gli utenti Windows, è necessario configurare la variabile d'ambiente per Visual Studio prima di eseguire il comando native-image. È possibile configurarla utilizzando il seguente comando:
"C:\Program Files (x86)\Microsoft Visual Studio\2017\Community\VC\Auxiliary\Build\vcvars64.bat"
Se il percorso di installazione e la versione di Visual Studio sono diversi, modificare di conseguenza le informazioni sul percorso correlato.
Compila con native-image
Ora usa il comando native-image per compilare il programma Java sopra in un file binario. Il formato del comando native-image è lo stesso del comando Java e include anche -cp e -jar. Questi parametri, come usare il comando Java per eseguire il programma, usano lo stesso metodo per la compilazione binaria, basta sostituire il comando da Java con native-image. Esegui il comando come segue.
native-image -cp . Hello
Dopo un periodo di compilazione, potrebbe consumare più CPU e memoria. È possibile ottenere un file binario compilato, il cui nome di output è predefinito con la lettera minuscola del nome della classe principale, che in questo caso è "hello". Se si utilizza Windows, sarà "hello.exe". Utilizzando il comando "file" per verificare il tipo di questo file, è possibile verificare che si tratti effettivamente di un file binario.
file hello
hello: Mach-O 64-bit executable x86_64
Esegui questo file e il suo output sarà lo stesso di quello ottenuto nel precedente use.java -cp . Ciao Il risultato è coerente
Hello World!
Analisi di NativeImage
Analisi con IDA
Utilizzare IDA per aprire il file hello compilato dai passaggi precedenti, fare clic su Esporta per visualizzare la tabella dei simboli, è possibile vedere il simbolo svm_code_section e il suo indirizzo è l'indirizzo di ingresso della funzione Java Main.
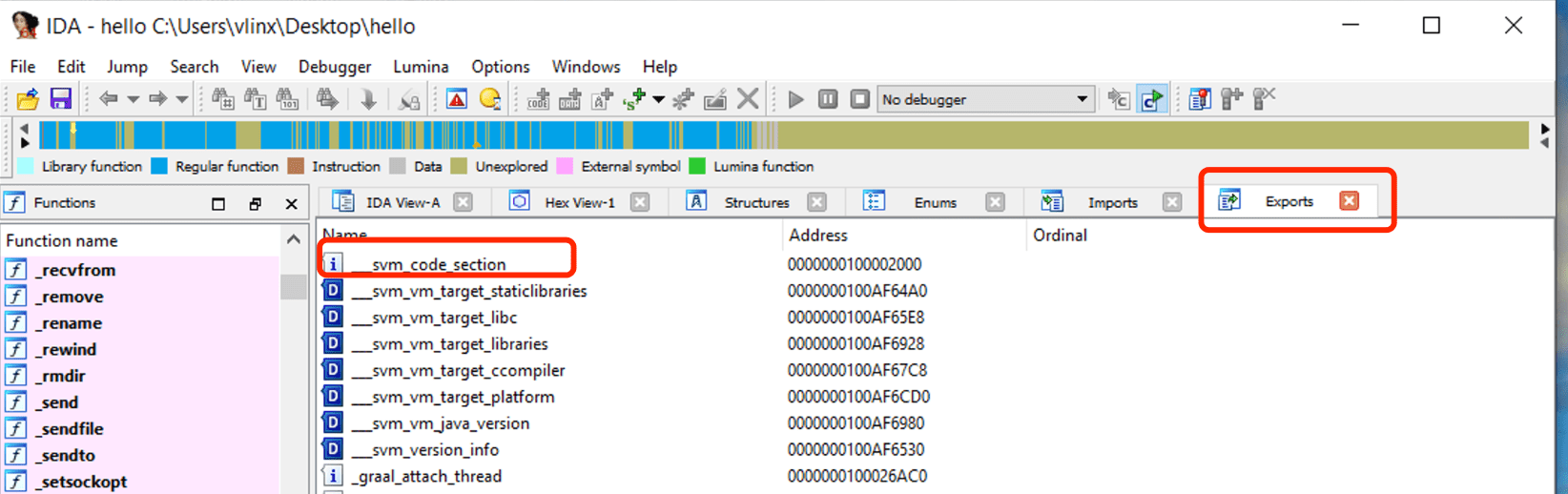
Vai a questo indirizzo per visualizzare il codice assembly
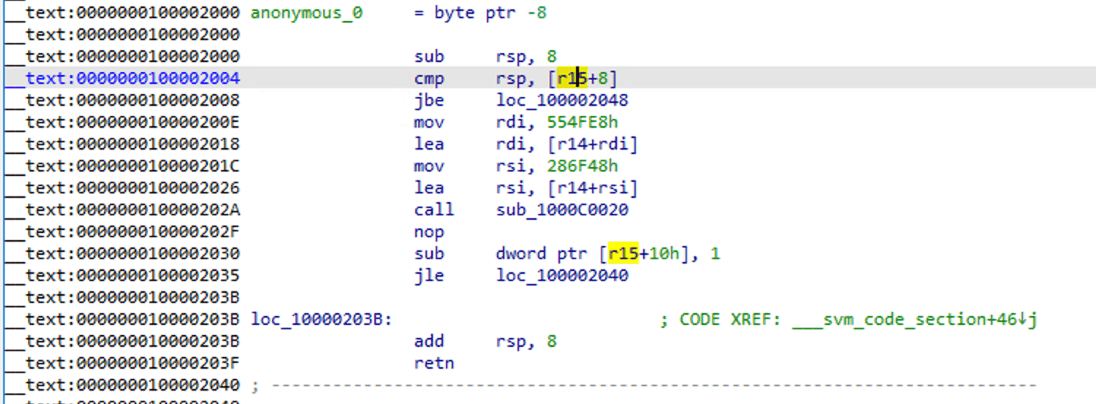
Puoi vedere che è diventata una funzione di assemblaggio standard, usa F5 per decompilare
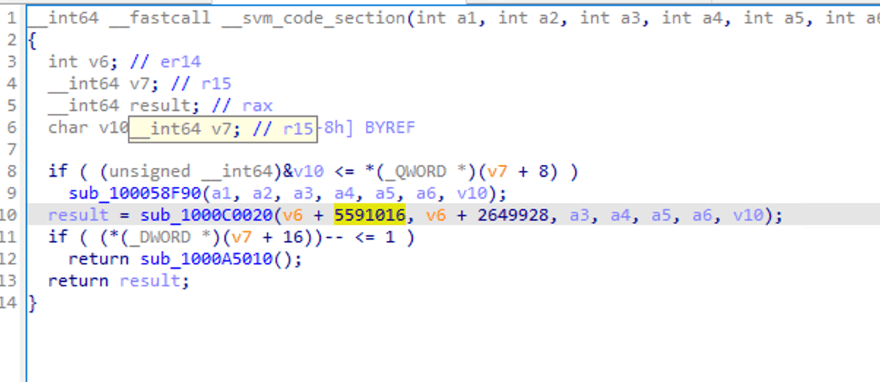
È possibile visualizzare alcune chiamate di funzione e alcuni parametri vengono passati, ma non è facile vederne la logica.
Facendo doppio clic su sub_1000C0020, diamo un'occhiata all'interno della chiamata di funzione. IDA segnala un errore di analisi.
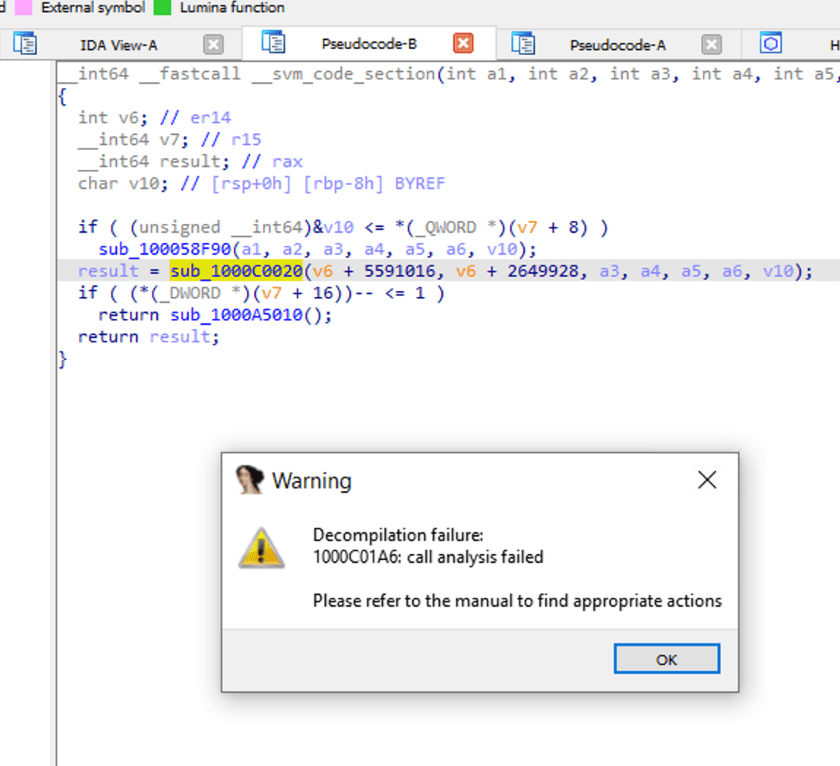
Logica di decompilazione di NativeImage
Poiché la compilazione di NativeImage si basa sulla compilazione JVM, può anche essere intesa come l'inclusione di codice binario in un livello di protezione della VM. Pertanto, strumenti come IDA non sono in grado di effettuare un reverse engineering efficace in assenza di informazioni corrispondenti e di misure di elaborazione mirate.
Tuttavia, indipendentemente dal formato, bytecode o binario, alcuni elementi di base dell'esecuzione della JVM sono inevitabilmente presenti, come le informazioni sulle classi, le informazioni sui campi, l'invocazione delle funzioni e il passaggio dei parametri. Sulla base di questa mentalità, lo strumento di analisi che ho sviluppato può raggiungere un certo livello di efficacia di ripristino e, con ulteriori miglioramenti, raggiungere un elevato livello di accuratezza del ripristino.
Scarica NativeImageAnalyzer
Visita https://github.com/vlinx-io/NativeImageAnalyzer per scaricare NativeImageAnalyzer
Eseguire il seguente comando per l'analisi inversa, attualmente analizzando solo la funzione Main della classe principale
native-image-analyzer hello
L'output è il seguente
java.io.PrintStream.writeln(java.io.PrintStream@0x554fe8, "Hello World!", rcx)
return
Diamo un'altra occhiata al codice originale.
public static void main(String[] args){
System.out.println("Hello World!");
}
Ora diamo un'occhiata alla definizione di System.out.
public static final PrintStream out = null;
Come si può notare, la variabile "out" della classe System è una variabile di tipo PrintStream, ed è una variabile statica. Durante la compilazione, NativeImage compila direttamente un'istanza di questa classe in una regione chiamata Heap, e il codice binario recupera direttamente questa istanza dalla regione Heap per l'invocazione. Diamo un'occhiata al codice originale dopo il ripristino.
java.io.PrintStream.writeln(java.io.PrintStream@0x554fe8, "Hello World!", rcx)
return
Questi java.io.PrintStream@0x554fe8 Viene semplicemente letto dall'area Heap java.io.PrintStream La variabile di istanza si trova all'indirizzo di memoria 0x554fe8.
我们再来看下java.io.PrintStream.writeln 函数的定义
private void writeln(String s) {
......
}
Qui possiamo vedere che c'è un argomento String nel writelin funzione, ma nel codice ripristinato, perché vengono passati tre argomenti? Primo writeln è un metodo membro della classe che nasconde solo uno this, La variabile punta al chiamante, che è il primo parametro passato, java.io.PrintStream@0x554fe8 Per quanto riguarda il terzo parametro rcx, è perché durante l'analisi del codice assembly è stato determinato che questa funzione veniva chiamata con tre parametri. Tuttavia, esaminando la definizione, sappiamo che in realtà questa funzione chiama solo due parametri. Anche questo è un aspetto che necessita di miglioramenti per questo strumento in futuro.
Un programma più complesso
Analizzeremo ora un programma più complesso, come il calcolo di una sequenza di Fibonacci, con il seguente codice
class Fibonacci {
public static void main(String[] args) {
int count = Integer.parseInt(args[0]);
int n1 = 0, n2 = 1, n3;
System.out.print(n1 + " " + n2);
for (int i = 2; i < count; ++i){
n3 = n1 + n2;
System.out.print(" " + n3);
n1 = n2;
n2 = n3;
}
System.out.println();
}
}
Compila ed esegui
javac Fibonacci.java
native-image -cp . Fibonacci
./fibonacci 10
0 1 1 2 3 5 8 13 21 34
Il codice ottenuto dopo il ripristino tramite NativeImageAnalyzer è il seguente
rdi = rdi[0]
ret_0 = java.lang.Integer.parseInt(rdi, 10)
sp_0x44 = ret_0
ret_1 = java.lang.StringConcatHelper.mix(1, 1)
ret_2 = java.lang.StringConcatHelper.mix(ret_1, 0)
sp_0x20 = java.io.PrintStream@0x554fe8
sp_0x18 = Class{[B}_1
tlab_0 = Class{[B}_1
tlab_0.length = ret_2<<ret_2>>32
sp_0x10 = tlab_0
ret_28 = ?java.lang.StringConcatHelper.prepend(tlab_0, " ", ret_2)
ret_29 = java.lang.StringConcatHelper.prepend(ret_28, sp_0x10, 0)
ret_30 = ?java.lang.StringConcatHelper.newString(sp_0x10, ret_29)
java.io.PrintStream.write(sp_0x20, ret_30)
if(sp_0x44>=3)
{
ret_7 = java.lang.StringConcatHelper.mix(1, 1)
tlab_1 = sp_0x18
tlab_1.length = ret_7<<ret_7>>32
sp_0x10 = " "
sp_0x8 = tlab_1
ret_22 = ?java.lang.StringConcatHelper.prepend(tlab_1, " ", ret_7)
ret_23 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_22)
rsi = ret_23
java.io.PrintStream.write(sp_0x20, ret_23)
rdi = 1
rdx = 1
rcx = 3
while(true)
{
if(sp_0x44<=rcx)
{
break
}
else
{
sp_0x34 = rcx
rdi = rdi+rdx
r9 = rdi
sp_0x30 = rdx
sp_0x2c = r9
ret_11 = java.lang.StringConcatHelper.mix(1, r9)
tlab_2 = sp_0x18
tlab_2.length = ret_11<<ret_11>>32
sp_0x8 = tlab_2
ret_17 = ?java.lang.StringConcatHelper.prepend(tlab_2, sp_0x10, ret_11)
ret_18 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_17)
rsi = ret_18
java.io.PrintStream.write(sp_0x20, ret_18)
rcx = sp_0x34+1
rdi = sp_0x30
rdx = sp_0x2c
}
}
}
java.io.PrintStream.newLine(sp_0x20, rsi)
return
Confronta il codice ripristinato con il codice originale.
rdi = rdi[0]
ret_0 = java.lang.Integer.parseInt(rdi, 10)
sp_0x44 = ret_0
Il corrispondente è
int count = Integer.parseInt(args[0]);
rdi è il registro utilizzato per passare il primo argomento di una funzione, se è Windows, allora rdi = rdi[0], che corrisponde a args[0], quindi, chiamare java.lang.Integer.parseInt per analizzare e ottenere un valore int, quindi assegnare il valore restituito a una variabile stack sp_0x44.
int n1 = 0, n2 = 1, n3;
System.out.print(n1 + " " + n2);
Corrispondente a.
ret_1 = java.lang.StringConcatHelper.mix(1, 1)
ret_2 = java.lang.StringConcatHelper.mix(ret_1, 0)
sp_0x20 = java.io.PrintStream@0x554fe8
sp_0x18 = Class{[B}_1
tlab_0 = Class{[B}_1
tlab_0.length = ret_2<<ret_2>>32
sp_0x10 = tlab_0
ret_28 = ?java.lang.StringConcatHelper.prepend(tlab_0, " ", ret_2)
ret_29 = java.lang.StringConcatHelper.prepend(ret_28, sp_0x10, 0)
ret_30 = ?java.lang.StringConcatHelper.newString(sp_0x10, ret_29)
java.io.PrintStream.write(sp_0x20, ret_30)
Nel nostro codice Java, la semplice operazione di concatenazione delle stringhe viene in realtà convertita in tre chiamate di funzione: StringConcatHelper.mix, StringConcatHelper.prepend, E StringConcatHelper.newString. Tra loro, StringConcatHelper.mix calcola la lunghezza della stringa concatenata, StringConcatHelper.prepend combina l'array byte[] che trasporta insieme il contenuto della stringa specifica e StringConcatHelper.newString genera un nuovo oggetto String dall'array byte[].
Nel codice sopra, vediamo due tipi di nomi di variabili, sp_0x18 E tlab_0Variabili che iniziano con sp_ indicano le variabili allocate sullo stack, mentre le variabili che iniziano con tlab_ Indica le variabili allocate nei buffer di allocazione locale dei thread. Questa è solo una spiegazione dell'origine di questi due tipi di nomi di variabili. Nel codice ripristinato, non c'è distinzione tra questi due tipi di variabili. Per informazioni relative ai buffer di allocazione locale dei thread, si prega di effettuare una ricerca autonoma.
Qui assegniamo tlab_0 A Class{[B}_1Il significato di Class{[B}_1 è un'istanza del tipo byte[]. [B rappresenta il descrittore Java per byte[], _1 indica che è la prima variabile di questo tipo. Se sono definite variabili successive per il tipo corrispondente, l'indice aumenterà di conseguenza, ad esempio Class{[B]}_2, Class{[B]}_3, ecc. La stessa rappresentazione si applica ad altri tipi, come Class{java.lang.String}_1, Class{java.util.HashMap}_2e così via.
La logica del codice soprastante spiega semplicemente la creazione di un'istanza di array byte[] e la sua assegnazione a tlab0. La lunghezza dell'array è ret_2 << ret_2 >> 32Il motivo per cui la lunghezza dell'array è ret_2 << ret_2 >> 32 Questo perché, quando si calcola la lunghezza di una stringa, è necessario convertire la lunghezza dell'array in base alla codifica. È possibile fare riferimento al codice pertinente in java.lang.String.java. Successivamente, la funzione prepend combina 0, 1 e spazi in tlab0, quindi genera un nuovo oggetto String ret_30 da tlab_0 e lo passa alla funzione java.io.PrintStream.write per la stampa dell'output. In realtà, qui i parametri ripristinati dalla funzione prepend non sono molto accurati e anche le loro posizioni sono errate. Questo è un aspetto che necessita di ulteriori miglioramenti in seguito.
Dopo aver convertito le due righe di codice Java in logica di esecuzione effettiva, il codice risulta ancora piuttosto complesso. In futuro, potrà essere semplificato analizzandolo e integrandolo sulla base del codice attualmente ripristinato.
Continua a camminare in avanti
for (int i = 2; i < count; ++i){
n3 = n1 + n2;
System.out.print(" " + n3);
n1 = n2;
n2 = n3;
}
System.out.println();
Il corrispondente è
if(sp_0x44>=3)
{
ret_7 = java.lang.StringConcatHelper.mix(1, 1)
tlab_1 = sp_0x18
tlab_1.length = ret_7<<ret_7>>32
sp_0x10 = " "
sp_0x8 = tlab_1
ret_22 = ?java.lang.StringConcatHelper.prepend(tlab_1, " ", ret_7)
ret_23 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_22)
rsi = ret_23
java.io.PrintStream.write(sp_0x20, ret_23)
rdi = 1
rdx = 1
rcx = 3
while(true)
{
if(sp_0x44<=rcx)
{
break
}
else
{
sp_0x34 = rcx
rdi = rdi+rdx
r9 = rdi
sp_0x30 = rdx
sp_0x2c = r9
ret_11 = java.lang.StringConcatHelper.mix(1, r9)
tlab_2 = sp_0x18
tlab_2.length = ret_11<<ret_11>>32
sp_0x8 = tlab_2
ret_17 = ?java.lang.StringConcatHelper.prepend(tlab_2, sp_0x10, ret_11)
ret_18 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_17)
rsi = ret_18
java.io.PrintStream.write(sp_0x20, ret_18)
rcx = sp_0x34+1
rdi = sp_0x30
rdx = sp_0x2c
}
}
}
java.io.PrintStream.newLine(sp_0x20, rsi)
return
sp_0x44 è il parametro che inseriamo nel programma, ovvero count. Il ciclo for nel codice Java verrà eseguito solo se count >= 3. Qui, il ciclo for viene trasformato in un ciclo while, mantenendo essenzialmente la stessa semantica. Al di fuori del ciclo while, il programma esegue la logica in cui count=3. Se count <= 3, il programma completa l'esecuzione e non entrerà più nel ciclo while. Questa potrebbe anche essere un'ottimizzazione effettuata da GraalVM durante la compilazione.
Diamo un'altra occhiata alla condizione di uscita del ciclo.
if(sp_0x44<=rcx)
{
break
}
Ciò corrisponde a
i < count
Allo stesso tempo, anche rcx si accumula durante ogni processo di iterazione.
sp_0x34 = rcx
rcx = sp_0x34+1
corrisponde a
++i
Ora, diamo un'occhiata a come la logica di aggiunta dei numeri nel corpo del ciclo si riflette nel codice ripristinato. Il codice originale è il seguente:
for(......){
......
n3 = n1 + n2;
n1 = n2;
n2 = n3;
......
}
Il codice dopo il ripristino è
while(true){
......
rdi = rdi+rdx -> n3 = n1 + n2
r9 = rdi -> r9 = n3
sp_0x30 = rdx -> sp_0x30 = n2
sp_0x2c = r9 -> sp_0x2c = n3
rdi = sp_0x30 -> n1 = sp_0x30 = n2
rdx = sp_0x2c -> n2 = sp_0x2c = n3
......
}
L'altro codice nel corpo del ciclo esegue la concatenazione delle stringhe e le operazioni di output come in precedenza. Il codice ripristinato riflette sostanzialmente la logica di esecuzione del codice originale.
Sono necessari ulteriori miglioramenti
Attualmente, questo strumento è in grado di ripristinare parzialmente il flusso di controllo del programma, di raggiungere un certo livello di analisi del flusso di dati e di ripristinare i nomi delle funzioni. Per diventare uno strumento completo e utilizzabile, deve ancora raggiungere i seguenti obiettivi:
Nome della funzione, parametri della funzione e ripristino del valore di ritorno della funzione più accurati
Informazioni accurate sugli oggetti e ripristino sul campo
Espressione più accurata e inferenza del tipo di oggetto
Integrazione e semplificazione delle dichiarazioni
Riflessioni sulla protezione binaria
Lo scopo di questo progetto è esplorare la fattibilità del reverse engineering di NativeImage. Sulla base dei risultati attuali, è fattibile effettuare il reverse engineering di NativeImage, il che comporta però sfide più complesse in termini di protezione del codice. Molti sviluppatori credono che compilare il software in formato binario possa garantire la sicurezza, trascurando la protezione del codice binario. Per il software scritto in C/C++, molti strumenti come IDA offrono già eccellenti risultati di reverse engineering, a volte esponendo persino più informazioni rispetto ai programmi Java. Ho persino visto alcuni software distribuiti in formato binario senza rimuovere le informazioni sui simboli dei nomi delle funzioni, il che equivale a eseguirli nudi.
Ogni codice è composto da logica. Finché contiene logica, è possibile ripristinarne la logica attraverso metodi inversi. L'unica differenza sta nella difficoltà del ripristino. La protezione del codice mira a massimizzare la difficoltà di tale ripristino.