Kỹ nghệ đảo ngược NativeImage
Khôi phục và bảo vệ mã Java là một vấn đề cũ và thường được thảo luận. Do định dạng byte-code được sử dụng để lưu trữ tệp class Java chứa nhiều thông tin meta, nó có thể dễ dàng được khôi phục về mã gốc. Để bảo vệ mã Java, ngành công nghiệp đã áp dụng nhiều phương pháp, chẳng hạn như làm rối mã, mã hóa bytecode, bảo vệ JNI, v.v. Tuy nhiên, bất kể phương pháp nào được sử dụng, vẫn có cách và phương tiện để bẻ khóa.
Biên dịch nhị phân luôn được coi là phương pháp bảo vệ mã tương đối hiệu quả. Biên dịch nhị phân của Java được hỗ trợ dưới dạng công nghệ AOT (Ahead of Time), tức là biên dịch trước.
Tuy nhiên, do tính chất động của ngôn ngữ Java, biên dịch nhị phân cần xử lý các vấn đề như reflection, dynamic proxy, tải JNI, v.v., gây ra nhiều khó khăn. Do đó, trong thời gian dài, thiếu một công cụ trưởng thành, đáng tin cậy và thích ứng cho biên dịch AOT trong Java có thể được ứng dụng rộng rãi trong môi trường sản xuất. (Trước đây có một công cụ gọi là Excelsior JET, nhưng dường như đã ngừng hoạt động.)
Vào tháng 5 năm 2019, Oracle phát hành GraalVM 19.0, một máy ảo hỗ trợ đa ngôn ngữ, đây là phiên bản sẵn sàng sản xuất đầu tiên. GraalVM cung cấp công cụ NativeImage có thể thực hiện biên dịch AOT cho chương trình Java. Sau nhiều năm phát triển, NativeImage giờ đã rất trưởng thành, và SpringBoot 3.0 có thể sử dụng nó để biên dịch toàn bộ dự án SpringBoot thành tệp thực thi. Tệp đã biên dịch có tốc độ khởi động nhanh, sử dụng bộ nhớ thấp và hiệu suất xuất sắc.
Vậy, đối với các chương trình Java đã bước vào kỷ nguyên biên dịch nhị phân, mã của chúng có còn dễ dàng dịch ngược như trong kỷ nguyên bytecode không? Các đặc điểm của tệp nhị phân được biên dịch bởi NativeImage là gì, và mức độ biên dịch nhị phân có đủ để bảo vệ mã quan trọng không?
Để khám phá những vấn đề này, gần đây chúng tôi đã phát triển một công cụ phân tích NativeImage, đã đạt được mức độ dịch ngược nhất định.
Dự án
https://github.com/vlinx-io/NativeImageAnalyzer
Tạo NativeImage
Đầu tiên, chúng ta cần tạo một NativeImage. NativeImage đến từ GraalVM. Để tải GraalVM, truy cập https://www.graalvm.org/ và tải phiên bản cho Java 17. Sau khi tải, thiết lập biến môi trường. Vì GraalVM chứa JDK, bạn có thể trực tiếp sử dụng nó để thực thi lệnh java.
Thêm $GRAALVM_HOME/bin vào biến môi trường, và sau đó chạy lệnh sau để cài đặt công cụ native-image
gu install native-image
Chương trình Java đơn giản
Viết một chương trình Java đơn giản, ví dụ:
public class Hello {
public static void main(String[] args){
System.out.println("Hello World!");
}
}
Biên dịch và chạy chương trình Java trên:
javac Hello.java
java -cp . Hello
Bạn sẽ nhận được đầu ra sau:
Hello World!
Chuẩn bị môi trường biên dịch
Nếu bạn là người dùng Windows, bạn cần cài đặt Visual Studio trước. Nếu bạn là người dùng Linux hoặc macOS, bạn cần cài đặt trước các công cụ như gcc và clang.
Đối với người dùng Windows, bạn cần thiết lập biến môi trường cho Visual Studio trước khi chạy lệnh native-image. Bạn có thể thiết lập bằng lệnh sau:
"C:\Program Files (x86)\Microsoft Visual Studio\2017\Community\VC\Auxiliary\Build\vcvars64.bat"
Nếu đường dẫn cài đặt và phiên bản Visual Studio khác nhau, vui lòng điều chỉnh thông tin đường dẫn tương ứng.
Biên dịch bằng native-image
Bây giờ sử dụng lệnh native-image để biên dịch chương trình Java trên thành tệp nhị phân. Định dạng lệnh native-image giống như định dạng lệnh java, cũng có các tham số -cp, -jar. Cách sử dụng lệnh java để thực thi chương trình, sử dụng cùng phương pháp cho biên dịch nhị phân, chỉ cần thay lệnh từ java thành native-image. Chạy lệnh sau
native-image -cp . Hello
Sau một thời gian biên dịch, có thể tiêu tốn nhiều CPU và bộ nhớ. Bạn có thể nhận được tệp nhị phân đã biên dịch, tên tệp đầu ra mặc định là chữ thường của class chính, trong trường hợp này là "hello". Nếu trên Windows, nó sẽ là "hello.exe". Sử dụng lệnh "file" để kiểm tra loại tệp này, bạn có thể thấy đây thực sự là tệp nhị phân.
file hello
hello: Mach-O 64-bit executable x86_64
Thực thi tệp này, đầu ra sẽ giống như kết quả nhận được khi sử dụng java -cp . Hello trước đó
Hello World!
Phân tích NativeImage
Phân tích bằng IDA
Sử dụng IDA để mở tệp hello đã biên dịch từ các bước trên, nhấp vào Exports để xem bảng ký hiệu, bạn có thể thấy ký hiệu svm_code_section, và địa chỉ của nó là địa chỉ vào của hàm Java Main.
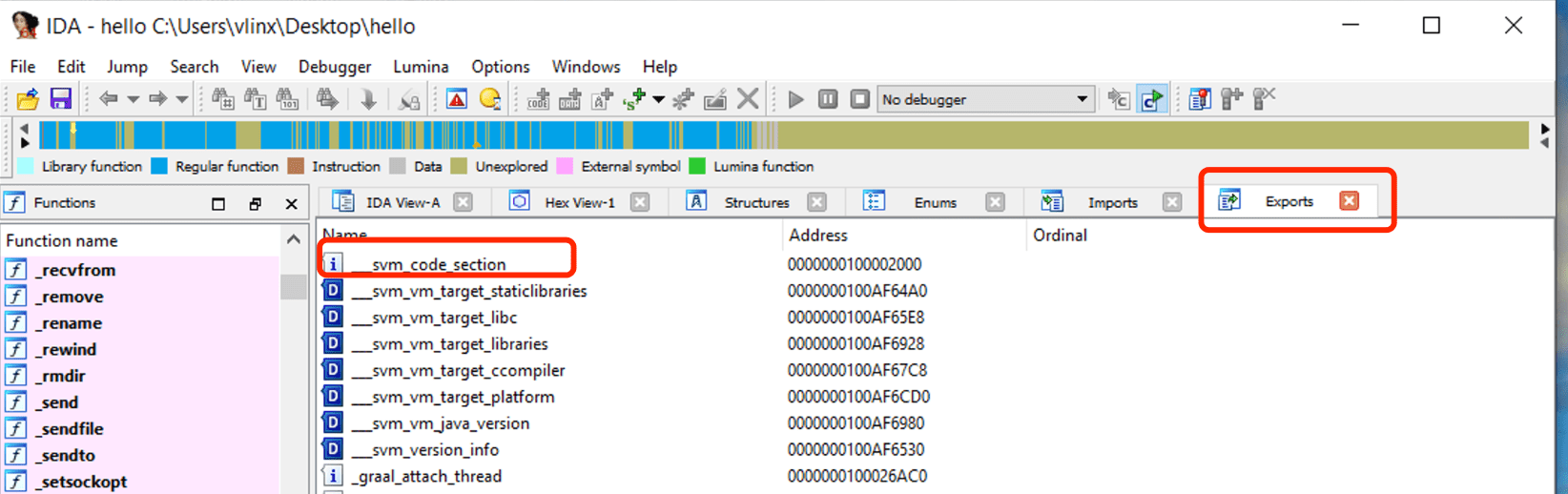
Điều hướng đến địa chỉ này để xem mã assembly
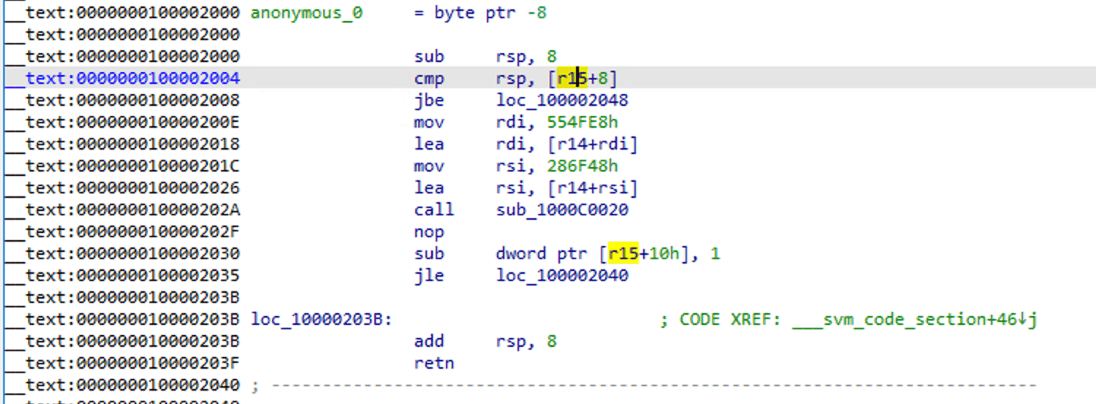
Bạn có thể thấy nó đã trở thành hàm assembly tiêu chuẩn, sử dụng F5 để dịch ngược
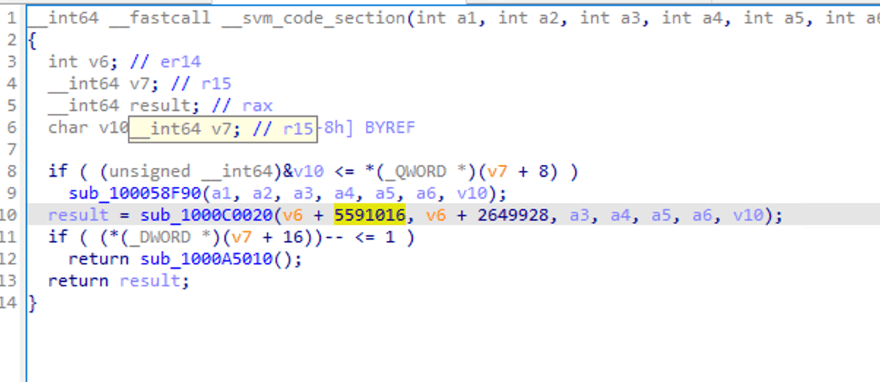
Một số lệnh gọi hàm có thể được nhìn thấy, và một số tham số được truyền, nhưng không dễ để thấy logic.
Khi chúng ta nhấp đúp vào sub_1000C0020, hãy xem bên trong lệnh gọi hàm. IDA thông báo phân tích thất bại.
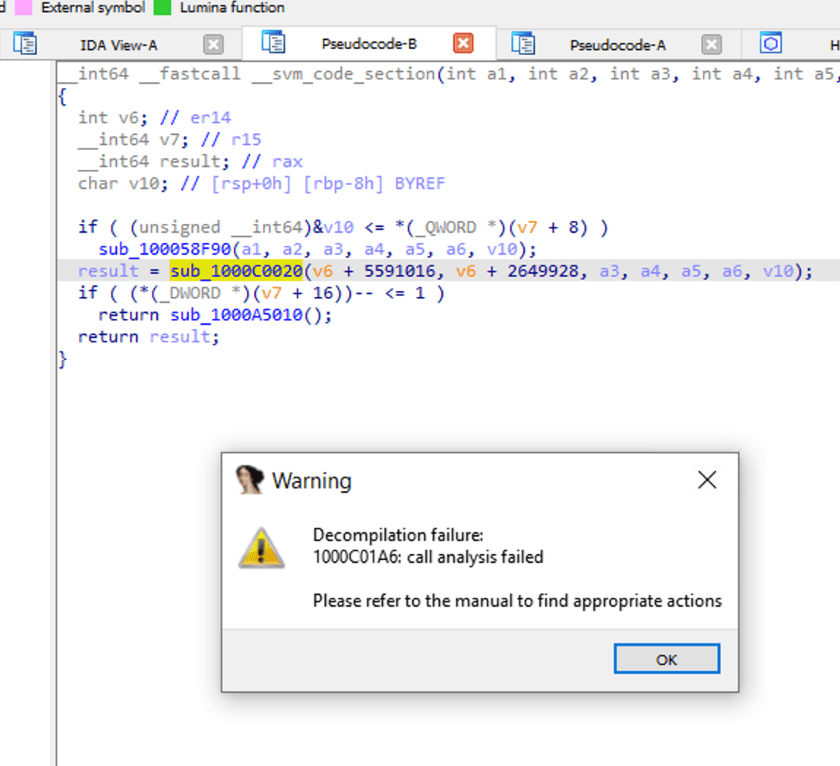
Logic dịch ngược của NativeImage
Vì biên dịch NativeImage dựa trên biên dịch JVM, nó cũng có thể được hiểu là bao bọc mã nhị phân với một lớp bảo vệ VM. Do đó, các công cụ như IDA không thể dịch ngược tốt khi thiếu thông tin tương ứng và các biện pháp xử lý có mục tiêu.
Tuy nhiên, bất kể định dạng là gì, dù là bytecode hay dạng nhị phân, một số yếu tố cơ bản của thực thi JVM chắc chắn phải tồn tại, chẳng hạn như thông tin class, thông tin trường, gọi hàm và truyền tham số. Dựa trên tư duy này, công cụ phân tích tôi đã phát triển có thể đạt được mức độ khôi phục nhất định và, với cải tiến thêm, có khả năng đạt độ chính xác khôi phục cao.
Phân tích bằng NativeImageAnalyzer
Truy cập https://github.com/vlinx-io/NativeImageAnalyzer để tải NativeImageAnalyzer
Chạy lệnh sau để phân tích đảo ngược, hiện tại chỉ phân tích hàm Main của class chính
native-image-analyzer hello
Đầu ra như sau
java.io.PrintStream.writeln(java.io.PrintStream@0x554fe8, "Hello World!", rcx)
return
Hãy xem lại mã gốc.
public static void main(String[] args){
System.out.println("Hello World!");
}
Bây giờ hãy xem định nghĩa của System.out.
public static final PrintStream out = null;
Bạn có thể thấy biến 'out' của class System là biến kiểu PrintStream, và nó là biến tĩnh. Trong quá trình biên dịch, NativeImage trực tiếp biên dịch một instance của class này vào vùng gọi là Heap, và mã nhị phân trực tiếp lấy instance này từ vùng Heap để gọi. Hãy xem mã gốc sau khi khôi phục.
java.io.PrintStream.writeln(java.io.PrintStream@0x554fe8, "Hello World!", rcx)
return
java.io.PrintStream@0x554fe8 chỉ là đọc từ vùng Heap instance biến java.io.PrintStream nằm tại địa chỉ bộ nhớ 0x554fe8.
Hãy xem định nghĩa hàm java.io.PrintStream.writeln
private void writeln(String s) {
......
}
Ở đây chúng ta có thể thấy có một tham số String trong hàm writeln, nhưng trong mã đã khôi phục, tại sao có ba tham số được truyền? Đầu tiên, writeln là phương thức thành viên của class chỉ ẩn một this, biến trỏ đến đối tượng gọi, đó là tham số đầu tiên được truyền, java.io.PrintStream@0x554fe8. Còn tham số thứ ba rcx, là vì trong quá trình phân tích mã assembly, đã xác định rằng hàm này được gọi với ba tham số. Tuy nhiên, khi xem xét định nghĩa, chúng ta biết hàm này thực tế chỉ gọi với hai tham số. Đây cũng là lĩnh vực cần cải thiện cho công cụ này trong tương lai.
Chương trình phức tạp hơn
Bây giờ chúng ta sẽ phân tích một chương trình phức tạp hơn, ví dụ tính dãy Fibonacci, với mã sau
class Fibonacci {
public static void main(String[] args) {
int count = Integer.parseInt(args[0]);
int n1 = 0, n2 = 1, n3;
System.out.print(n1 + " " + n2);
for (int i = 2; i < count; ++i){
n3 = n1 + n2;
System.out.print(" " + n3);
n1 = n2;
n2 = n3;
}
System.out.println();
}
}
Biên dịch và thực thi
javac Fibonacci.java
native-image -cp . Fibonacci
./fibonacci 10
0 1 1 2 3 5 8 13 21 34
Mã thu được sau khi khôi phục bằng NativeImageAnalyzer như sau
rdi = rdi[0]
ret_0 = java.lang.Integer.parseInt(rdi, 10)
sp_0x44 = ret_0
ret_1 = java.lang.StringConcatHelper.mix(1, 1)
ret_2 = java.lang.StringConcatHelper.mix(ret_1, 0)
sp_0x20 = java.io.PrintStream@0x554fe8
sp_0x18 = Class{[B}_1
tlab_0 = Class{[B}_1
tlab_0.length = ret_2<<ret_2>>32
sp_0x10 = tlab_0
ret_28 = ?java.lang.StringConcatHelper.prepend(tlab_0, " ", ret_2)
ret_29 = java.lang.StringConcatHelper.prepend(ret_28, sp_0x10, 0)
ret_30 = ?java.lang.StringConcatHelper.newString(sp_0x10, ret_29)
java.io.PrintStream.write(sp_0x20, ret_30)
if(sp_0x44>=3)
{
ret_7 = java.lang.StringConcatHelper.mix(1, 1)
tlab_1 = sp_0x18
tlab_1.length = ret_7<<ret_7>>32
sp_0x10 = " "
sp_0x8 = tlab_1
ret_22 = ?java.lang.StringConcatHelper.prepend(tlab_1, " ", ret_7)
ret_23 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_22)
rsi = ret_23
java.io.PrintStream.write(sp_0x20, ret_23)
rdi = 1
rdx = 1
rcx = 3
while(true)
{
if(sp_0x44<=rcx)
{
break
}
else
{
sp_0x34 = rcx
rdi = rdi+rdx
r9 = rdi
sp_0x30 = rdx
sp_0x2c = r9
ret_11 = java.lang.StringConcatHelper.mix(1, r9)
tlab_2 = sp_0x18
tlab_2.length = ret_11<<ret_11>>32
sp_0x8 = tlab_2
ret_17 = ?java.lang.StringConcatHelper.prepend(tlab_2, sp_0x10, ret_11)
ret_18 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_17)
rsi = ret_18
java.io.PrintStream.write(sp_0x20, ret_18)
rcx = sp_0x34+1
rdi = sp_0x30
rdx = sp_0x2c
}
}
}
java.io.PrintStream.newLine(sp_0x20, rsi)
return
So sánh mã đã khôi phục với mã gốc.
rdi = rdi[0]
ret_0 = java.lang.Integer.parseInt(rdi, 10)
sp_0x44 = ret_0
Tương ứng với
int count = Integer.parseInt(args[0]);
rdi là thanh ghi dùng để truyền tham số đầu tiên của hàm, nếu là Windows thì rdi = rdi[0], tương ứng với args[0]. Sau đó, gọi java.lang.Integer.parseInt để phân tích và lấy giá trị int, rồi gán giá trị trả về cho biến trên ngăn xếp sp_0x44.
int n1 = 0, n2 = 1, n3;
System.out.print(n1 + " " + n2);
Tương ứng với
ret_1 = java.lang.StringConcatHelper.mix(1, 1)
ret_2 = java.lang.StringConcatHelper.mix(ret_1, 0)
sp_0x20 = java.io.PrintStream@0x554fe8
sp_0x18 = Class{[B}_1
tlab_0 = Class{[B}_1
tlab_0.length = ret_2<<ret_2>>32
sp_0x10 = tlab_0
ret_28 = ?java.lang.StringConcatHelper.prepend(tlab_0, " ", ret_2)
ret_29 = java.lang.StringConcatHelper.prepend(ret_28, sp_0x10, 0)
ret_30 = ?java.lang.StringConcatHelper.newString(sp_0x10, ret_29)
java.io.PrintStream.write(sp_0x20, ret_30)
Trong mã Java, thao tác nối chuỗi đơn giản thực tế được chuyển đổi thành ba lệnh gọi hàm: StringConcatHelper.mix, StringConcatHelper.prepend, và StringConcatHelper.newString. Trong đó, StringConcatHelper.mix tính toán độ dài chuỗi nối, StringConcatHelper.prepend kết hợp mảng byte[] mang nội dung chuỗi cụ thể lại với nhau, và StringConcatHelper.newString tạo đối tượng String mới từ mảng byte[].
Trong mã trên, chúng ta thấy hai loại tên biến, sp_0x18 và tlab_0. Biến bắt đầu bằng sp_ chỉ ra biến được cấp phát trên ngăn xếp, trong khi biến bắt đầu bằng tlab_ chỉ ra biến được cấp phát trên Thread Local Allocation Buffers. Đây chỉ là giải thích về nguồn gốc của hai loại tên biến này. Trong mã đã khôi phục, không có sự phân biệt giữa hai loại biến này. Để biết thông tin liên quan đến Thread Local Allocation Buffers, vui lòng tự tìm kiếm.
Ở đây chúng ta gán tlab_0 cho Class{[B}_1. Ý nghĩa của Class{[B}_1 là một instance kiểu byte[]. [B đại diện cho mô tả Java cho byte[], _1 chỉ ra đây là biến đầu tiên của kiểu này. Nếu có các biến tiếp theo được định nghĩa cho kiểu tương ứng, chỉ mục sẽ tăng tương ứng, chẳng hạn Class{[B]}_2, Class{[B]}_3, v.v. Biểu diễn tương tự áp dụng cho các kiểu khác, chẳng hạn Class{java.lang.String}_1, Class{java.util.HashMap}_2, v.v.
Logic của đoạn mã trên giải thích đơn giản việc tạo instance mảng byte[] và gán cho tlab0. Độ dài mảng là ret_2 << ret_2 >> 32. Lý do độ dài mảng là ret_2 << ret_2 >> 32 là vì khi tính độ dài String, cần chuyển đổi độ dài mảng dựa trên mã hóa. Bạn có thể tham khảo mã liên quan trong java.lang.String.java. Tiếp theo, hàm prepend kết hợp 0, 1 và dấu cách vào tlab0, sau đó tạo đối tượng String mới ret_30 từ tlab_0 và truyền cho hàm java.io.PrintStream.write để in đầu ra. Thực tế, các tham số được khôi phục bởi hàm prepend không rất chính xác và vị trí cũng không đúng. Đây là lĩnh vực cần cải thiện thêm sau này.
Sau khi chuyển đổi hai dòng mã Java thành logic thực thi thực tế, nó vẫn khá phức tạp. Trong tương lai, có thể đơn giản hóa bằng cách phân tích và tích hợp trên cơ sở mã đã khôi phục hiện tại.
Tiếp tục đi tới
for (int i = 2; i < count; ++i){
n3 = n1 + n2;
System.out.print(" " + n3);
n1 = n2;
n2 = n3;
}
System.out.println();
Tương ứng với
if(sp_0x44>=3)
{
ret_7 = java.lang.StringConcatHelper.mix(1, 1)
tlab_1 = sp_0x18
tlab_1.length = ret_7<<ret_7>>32
sp_0x10 = " "
sp_0x8 = tlab_1
ret_22 = ?java.lang.StringConcatHelper.prepend(tlab_1, " ", ret_7)
ret_23 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_22)
rsi = ret_23
java.io.PrintStream.write(sp_0x20, ret_23)
rdi = 1
rdx = 1
rcx = 3
while(true)
{
if(sp_0x44<=rcx)
{
break
}
else
{
sp_0x34 = rcx
rdi = rdi+rdx
r9 = rdi
sp_0x30 = rdx
sp_0x2c = r9
ret_11 = java.lang.StringConcatHelper.mix(1, r9)
tlab_2 = sp_0x18
tlab_2.length = ret_11<<ret_11>>32
sp_0x8 = tlab_2
ret_17 = ?java.lang.StringConcatHelper.prepend(tlab_2, sp_0x10, ret_11)
ret_18 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_17)
rsi = ret_18
java.io.PrintStream.write(sp_0x20, ret_18)
rcx = sp_0x34+1
rdi = sp_0x30
rdx = sp_0x2c
}
}
}
java.io.PrintStream.newLine(sp_0x20, rsi)
return
sp_0x44 là tham số chúng ta nhập vào chương trình, tức là count. Vòng lặp for trong mã Java chỉ được thực thi nếu count >= 3. Ở đây, vòng lặp for được chuyển đổi lại thành vòng lặp while, về cơ bản có cùng ngữ nghĩa. Bên ngoài vòng lặp while, chương trình thực thi logic khi count=3. Nếu count <= 3, chương trình hoàn tất thực thi và sẽ không vào vòng lặp while nữa. Đây cũng có thể là tối ưu hóa được GraalVM thực hiện trong quá trình biên dịch.
Hãy xem điều kiện thoát vòng lặp.
if(sp_0x44<=rcx)
{
break
}
Tương ứng với
i < count
Đồng thời, rcx cũng đang tích lũy trong mỗi lần lặp.
sp_0x34 = rcx
rcx = sp_0x34+1
tương ứng với
++i
Tiếp theo, hãy xem logic cộng số trong thân vòng lặp được phản ánh như thế nào trong mã đã khôi phục. Mã gốc như sau:
for(......){
......
n3 = n1 + n2;
n1 = n2;
n2 = n3;
......
}
Mã sau khôi phục là
while(true){
......
rdi = rdi+rdx -> n3 = n1 + n2
r9 = rdi -> r9 = n3
sp_0x30 = rdx -> sp_0x30 = n2
sp_0x2c = r9 -> sp_0x2c = n3
rdi = sp_0x30 -> n1 = sp_0x30 = n2
rdx = sp_0x2c -> n2 = sp_0x2c = n3
......
}
Mã khác trong thân vòng lặp thực hiện các thao tác nối chuỗi và đầu ra như trước. Mã đã khôi phục về cơ bản phản ánh logic thực thi của mã gốc.
Cần cải tiến thêm
Hiện tại, công cụ này có thể khôi phục một phần luồng điều khiển chương trình, đạt được mức độ phân tích luồng dữ liệu và khôi phục tên hàm nhất định. Để trở thành công cụ hoàn chỉnh và sử dụng được, nó vẫn cần hoàn thiện:
Khôi phục chính xác hơn tên hàm, tham số hàm và giá trị trả về
Khôi phục chính xác thông tin đối tượng và trường
Suy luận chính xác hơn về biểu thức và kiểu đối tượng
Tích hợp và đơn giản hóa câu lệnh
Suy nghĩ về bảo vệ nhị phân
Mục đích của dự án này là khám phá tính khả thi của kỹ nghệ đảo ngược NativeImage. Dựa trên các thành tựu hiện tại, việc dịch ngược NativeImage là khả thi, điều này cũng mang đến thách thức cao hơn cho bảo vệ mã. Nhiều nhà phát triển tin rằng biên dịch phần mềm thành nhị phân có thể đảm bảo an toàn, bỏ qua việc bảo vệ mã nhị phân. Đối với phần mềm viết bằng C/C++, nhiều công cụ như IDA đã có hiệu quả dịch ngược xuất sắc, đôi khi còn lộ nhiều thông tin hơn cả chương trình Java. Tôi thậm chí đã thấy một số phần mềm phân phối ở dạng nhị phân mà không xóa thông tin ký hiệu tên hàm, tương đương với chạy trần.
Bất kỳ mã nào đều được cấu thành từ logic. Miễn là nó chứa logic, có thể khôi phục logic đó thông qua các phương tiện đảo ngược. Sự khác biệt duy nhất nằm ở độ khó của việc khôi phục. Bảo vệ mã là để tối đa hóa độ khó của việc khôi phục đó.