NativeImage Reverse Engineering
Die Wiederherstellung und der Schutz von Java-Code ist ein altes und oft diskutiertes Thema. Aufgrund des Bytecode-Formats, in dem Java-Klassendateien gespeichert werden und das viele Meta-Informationen enthält, kann der Code leicht in seinen ursprünglichen Zustand wiederhergestellt werden. Um Java-Code zu schützen, hat die Branche viele Methoden eingesetzt, wie Obfuskation, Bytecode-Verschlüsselung, JNI-Schutz und so weiter. Unabhängig von der verwendeten Methode gibt es jedoch immer noch Wege und Mittel, ihn zu knacken.
Die binäre Kompilierung wurde immer als eine relativ effektive Methode zum Code-Schutz angesehen. Die binäre Kompilierung von Java wird als AOT-Technologie (Ahead of Time) unterstützt, was Vorkompilierung bedeutet.
Aufgrund der dynamischen Natur der Java-Sprache muss die binäre Kompilierung jedoch Probleme wie Reflection, dynamische Proxys, JNI-Laden usw. bewältigen, was viele Schwierigkeiten bereitet. Daher fehlte lange Zeit ein ausgereiftes, zuverlässiges und anpassungsfähiges Tool für die AOT-Kompilierung in Java, das in Produktionsumgebungen weit verbreitet eingesetzt werden konnte. (Es gab einmal ein Tool namens Excelsior JET, aber es scheint mittlerweile eingestellt zu sein.)
Im Mai 2019 veröffentlichte Oracle GraalVM 19.0, eine mehrsprachig unterstützende virtuelle Maschine, die ihre erste produktionsreife Version war. GraalVM bietet ein NativeImage-Tool, das die AOT-Kompilierung von Java-Programmen ermöglicht. Nach mehreren Jahren der Entwicklung ist NativeImage nun sehr ausgereift, und SpringBoot 3.0 kann es verwenden, um das gesamte SpringBoot-Projekt in eine ausführbare Datei zu kompilieren. Die kompilierte Datei hat eine schnelle Startgeschwindigkeit, einen geringen Speicherverbrauch und eine hervorragende Leistung.
Ist also für Java-Programme, die in das Zeitalter der binären Kompilierung eingetreten sind, ihr Code immer noch so leicht reversibel wie in der Bytecode-Ära? Welche Eigenschaften haben die von NativeImage kompilierten Binärdateien, und reicht die Intensität der binären Kompilierung aus, um wichtigen Code zu schützen?
Um diese Fragen zu untersuchen, haben wir kürzlich ein NativeImage-Analysetool entwickelt, das einen gewissen Grad an Reverse-Engineering-Effekt erzielt hat.
Projekt
https://github.com/vlinx-io/NativeImageAnalyzer
NativeImage generieren
Zunächst müssen wir ein NativeImage generieren. NativeImage stammt von GraalVM. Um GraalVM herunterzuladen, gehen Sie zu https://www.graalvm.org/ und laden Sie die Version für Java 17 herunter. Nach dem Download setzen Sie die Umgebungsvariable. Da GraalVM ein JDK enthält, können Sie es direkt verwenden, um den Java-Befehl auszuführen.
Fügen Sie $GRAALVM_HOME/bin zur Umgebungsvariable hinzu und führen Sie dann den folgenden Befehl aus, um das native-image-Tool zu installieren
gu install native-image
Ein einfaches Java-Programm
Schreiben Sie ein einfaches Java-Programm, zum Beispiel:
public class Hello {
public static void main(String[] args){
System.out.println("Hello World!");
}
}
Kompilieren und führen Sie das obige Java-Programm aus:
javac Hello.java
java -cp . Hello
Sie erhalten die folgende Ausgabe:
Hello World!
Vorbereitung der Kompilierungsumgebung
Wenn Sie ein Windows-Benutzer sind, müssen Sie zunächst Visual Studio installieren. Wenn Sie ein Linux- oder macOS-Benutzer sind, müssen Sie zuvor Tools wie gcc und clang installieren.
Für Windows-Benutzer müssen Sie die Umgebungsvariable für Visual Studio einrichten, bevor Sie den native-image-Befehl ausführen. Sie können sie mit dem folgenden Befehl einrichten:
"C:\Program Files (x86)\Microsoft Visual Studio\2017\Community\VC\Auxiliary\Build\vcvars64.bat"
Wenn der Installationspfad und die Version von Visual Studio unterschiedlich sind, passen Sie bitte die zugehörigen Pfadinformationen entsprechend an.
Mit native-image kompilieren
Verwenden Sie nun den native-image-Befehl, um das obige Java-Programm in eine Binärdatei zu kompilieren. Das Format des native-image-Befehls ist dasselbe wie das des Java-Befehls und hat auch die Parameter -cp und -jar. Wie Sie den Java-Befehl zum Ausführen des Programms verwenden, können Sie dieselbe Methode für die binäre Kompilierung verwenden, ersetzen Sie nur den Befehl von java durch native-image. Führen Sie den folgenden Befehl aus
native-image -cp . Hello
Nach einer Kompilierungszeit, die mehr CPU und Speicher verbrauchen kann, erhalten Sie eine kompilierte Binärdatei. Der Ausgabedateiname ist standardmäßig der Kleinbuchstabe des Hauptklassennamens, in diesem Fall "hello". Unter Windows wird es "hello.exe" sein. Verwenden Sie den Befehl "file", um den Typ dieser Datei zu überprüfen. Sie können sehen, dass es sich tatsächlich um eine Binärdatei handelt.
file hello
hello: Mach-O 64-bit executable x86_64
Führen Sie diese Datei aus, und ihre Ausgabe wird dieselbe sein wie die zuvor erhaltene mit java -cp . Hello
Hello World!
NativeImage analysieren
Analyse mit IDA
Verwenden Sie IDA, um die im vorherigen Schritt kompilierte hello-Datei zu öffnen. Klicken Sie auf Exports, um die Symboltabelle anzuzeigen. Sie sehen das Symbol svm_code_section, und seine Adresse ist die Einstiegsadresse der Java-Main-Funktion.
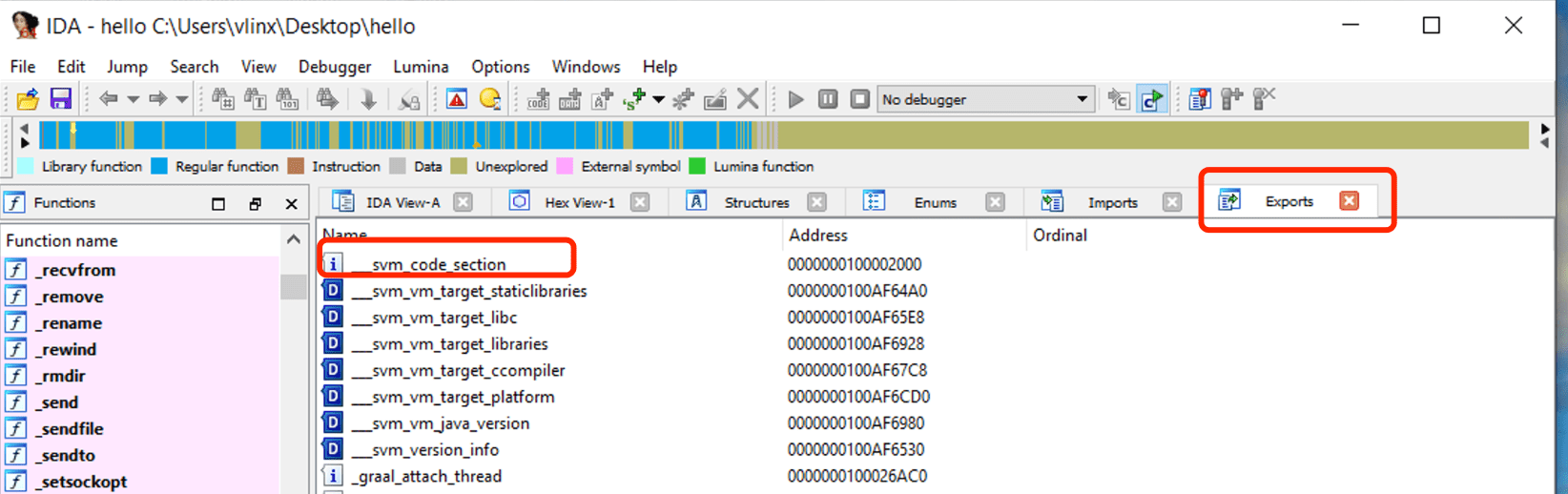
Navigieren Sie zu dieser Adresse, um den Assembler-Code anzuzeigen
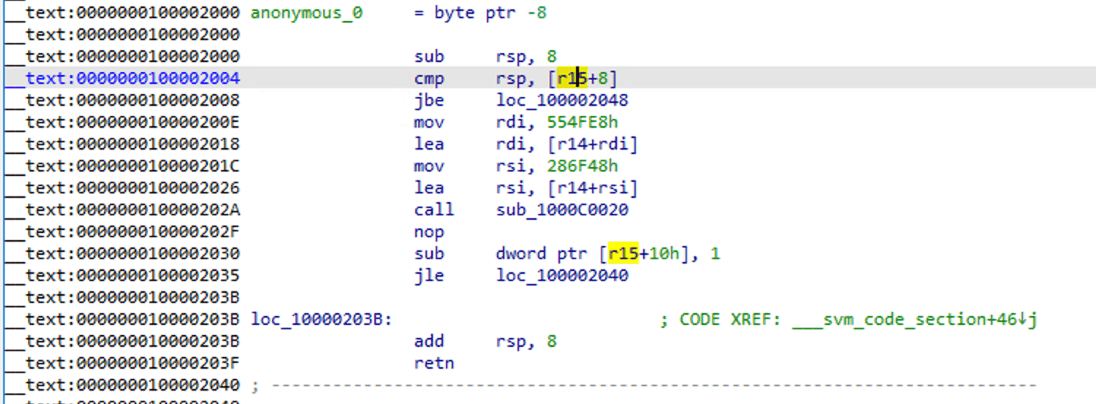
Sie können sehen, dass es zu einer Standard-Assemblerfunktion geworden ist. Verwenden Sie F5 zum Dekompilieren
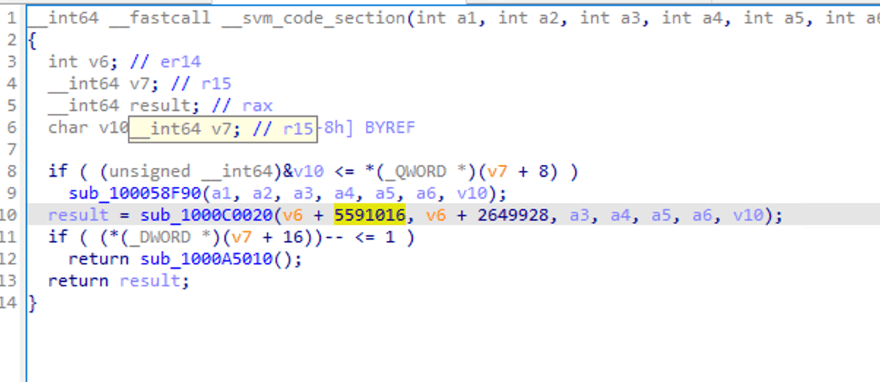
Einige Funktionsaufrufe sind zu sehen, und einige Parameter werden übergeben, aber die Logik ist nicht leicht erkennbar.
Wenn wir auf sub_1000C0020 doppelklicken, schauen wir uns den Funktionsaufruf an. IDA meldet einen Analysefehler.
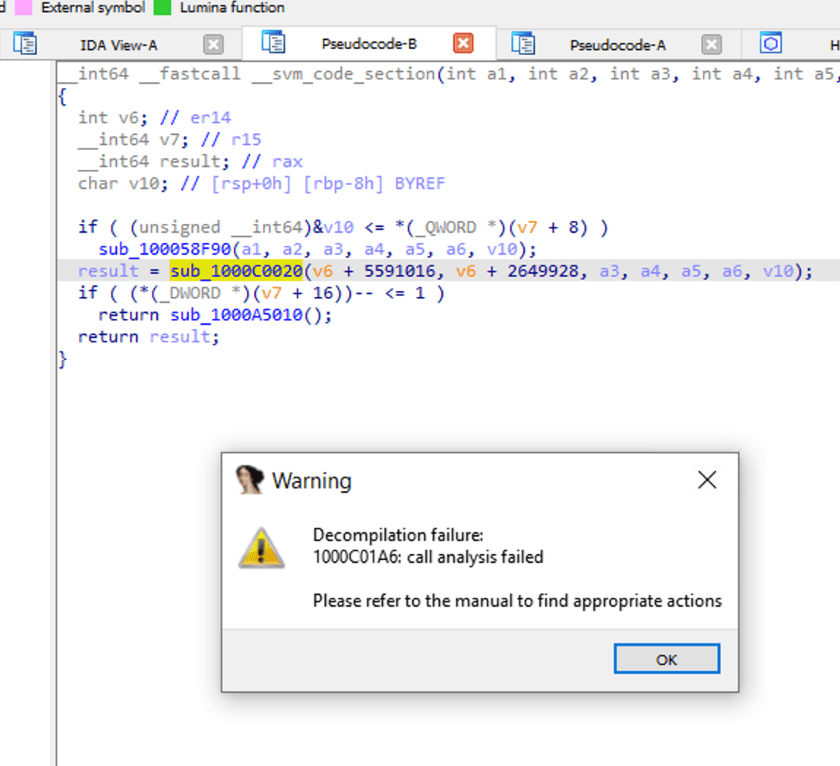
Dekompilierungslogik von NativeImage
Da die Kompilierung von NativeImage auf der JVM-Kompilierung basiert, kann man es auch so verstehen, dass binärer Code mit einer Schicht VM-Schutz umhüllt wird. Daher können Tools wie IDA in Abwesenheit entsprechender Informationen und gezielter Verarbeitungsmaßnahmen es nicht gut zurückentwickeln.
Unabhängig vom Format, ob Bytecode oder binäre Form, müssen jedoch einige grundlegende Elemente der JVM-Ausführung vorhanden sein, wie Klasseninformationen, Feldinformationen, Funktionsaufrufe und Parameterübergabe. Basierend auf dieser Denkweise kann das von mir entwickelte Analysetool einen gewissen Grad an Wiederherstellungseffekt erzielen und mit weiterer Verbesserung die Fähigkeit haben, eine hohe Wiederherstellungsgenauigkeit zu erreichen.
Analyse mit NativeImageAnalyzer
Besuchen Sie https://github.com/vlinx-io/NativeImageAnalyzer, um NativeImageAnalyzer herunterzuladen
Führen Sie den folgenden Befehl für die Reverse-Analyse aus. Derzeit wird nur die Main-Funktion der Hauptklasse analysiert
native-image-analyzer hello
Die Ausgabe ist wie folgt
java.io.PrintStream.writeln(java.io.PrintStream@0x554fe8, "Hello World!", rcx)
return
Schauen wir uns den ursprünglichen Code erneut an.
public static void main(String[] args){
System.out.println("Hello World!");
}
Schauen wir uns nun die Definition von System.out an.
public static final PrintStream out = null;
Sie können sehen, dass die Variable 'out' der System-Klasse eine Variable vom Typ PrintStream ist und eine statische Variable. Während der Kompilierung kompiliert NativeImage eine Instanz dieser Klasse direkt in einen Bereich namens Heap, und der Binärcode ruft diese Instanz direkt aus dem Heap-Bereich ab. Schauen wir uns den wiederhergestellten Code an.
java.io.PrintStream.writeln(java.io.PrintStream@0x554fe8, "Hello World!", rcx)
return
Dieses java.io.PrintStream@0x554fe8 wird einfach aus dem Heap-Bereich gelesen. Die java.io.PrintStream-Instanzvariable befindet sich an der Speicheradresse 0x554fe8.
Schauen wir uns die Definition der Funktion java.io.PrintStream.writeln an
private void writeln(String s) {
......
}
Hier können wir sehen, dass es ein String-Argument in der writeln-Funktion gibt, aber im wiederhergestellten Code werden drei Argumente übergeben. Erstens ist writeln eine Klassenmitgliedsmethode, die nur ein this verbirgt. Die Variable zeigt auf den Aufrufer, das ist der erste übergebene Parameter, java.io.PrintStream@0x554fe8. Was den dritten Parameter rcx betrifft, so wurde bei der Analyse des Assembler-Codes festgestellt, dass diese Funktion mit drei Parametern aufgerufen wurde. Bei der Überprüfung der Definition wissen wir jedoch, dass diese Funktion tatsächlich nur zwei Parameter aufruft. Dies ist auch ein Bereich, der in Zukunft für dieses Tool verbessert werden muss.
Ein komplexeres Programm
Wir werden nun ein komplexeres Programm analysieren, zum Beispiel die Berechnung einer Fibonacci-Folge, mit dem folgenden Code
class Fibonacci {
public static void main(String[] args) {
int count = Integer.parseInt(args[0]);
int n1 = 0, n2 = 1, n3;
System.out.print(n1 + " " + n2);
for (int i = 2; i < count; ++i){
n3 = n1 + n2;
System.out.print(" " + n3);
n1 = n2;
n2 = n3;
}
System.out.println();
}
}
Kompilieren und ausführen
javac Fibonacci.java
native-image -cp . Fibonacci
./fibonacci 10
0 1 1 2 3 5 8 13 21 34
Der nach der Wiederherstellung mit NativeImageAnalyzer erhaltene Code lautet wie folgt
rdi = rdi[0]
ret_0 = java.lang.Integer.parseInt(rdi, 10)
sp_0x44 = ret_0
ret_1 = java.lang.StringConcatHelper.mix(1, 1)
ret_2 = java.lang.StringConcatHelper.mix(ret_1, 0)
sp_0x20 = java.io.PrintStream@0x554fe8
sp_0x18 = Class{[B}_1
tlab_0 = Class{[B}_1
tlab_0.length = ret_2<<ret_2>>32
sp_0x10 = tlab_0
ret_28 = ?java.lang.StringConcatHelper.prepend(tlab_0, " ", ret_2)
ret_29 = java.lang.StringConcatHelper.prepend(ret_28, sp_0x10, 0)
ret_30 = ?java.lang.StringConcatHelper.newString(sp_0x10, ret_29)
java.io.PrintStream.write(sp_0x20, ret_30)
if(sp_0x44>=3)
{
ret_7 = java.lang.StringConcatHelper.mix(1, 1)
tlab_1 = sp_0x18
tlab_1.length = ret_7<<ret_7>>32
sp_0x10 = " "
sp_0x8 = tlab_1
ret_22 = ?java.lang.StringConcatHelper.prepend(tlab_1, " ", ret_7)
ret_23 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_22)
rsi = ret_23
java.io.PrintStream.write(sp_0x20, ret_23)
rdi = 1
rdx = 1
rcx = 3
while(true)
{
if(sp_0x44<=rcx)
{
break
}
else
{
sp_0x34 = rcx
rdi = rdi+rdx
r9 = rdi
sp_0x30 = rdx
sp_0x2c = r9
ret_11 = java.lang.StringConcatHelper.mix(1, r9)
tlab_2 = sp_0x18
tlab_2.length = ret_11<<ret_11>>32
sp_0x8 = tlab_2
ret_17 = ?java.lang.StringConcatHelper.prepend(tlab_2, sp_0x10, ret_11)
ret_18 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_17)
rsi = ret_18
java.io.PrintStream.write(sp_0x20, ret_18)
rcx = sp_0x34+1
rdi = sp_0x30
rdx = sp_0x2c
}
}
}
java.io.PrintStream.newLine(sp_0x20, rsi)
return
Vergleichen wir den wiederhergestellten Code mit dem Originalcode.
rdi = rdi[0]
ret_0 = java.lang.Integer.parseInt(rdi, 10)
sp_0x44 = ret_0
Dies entspricht
int count = Integer.parseInt(args[0]);
rdi ist das Register, das verwendet wird, um das erste Argument einer Funktion zu übergeben. Unter Windows wäre es rdi = rdi[0], was args[0] entspricht. Danach wird java.lang.Integer.parseInt aufgerufen, um einen int-Wert zu parsen, dann wird der Rückgabewert einer Stack-Variable sp_0x44 zugewiesen.
int n1 = 0, n2 = 1, n3;
System.out.print(n1 + " " + n2);
Entspricht:
ret_1 = java.lang.StringConcatHelper.mix(1, 1)
ret_2 = java.lang.StringConcatHelper.mix(ret_1, 0)
sp_0x20 = java.io.PrintStream@0x554fe8
sp_0x18 = Class{[B}_1
tlab_0 = Class{[B}_1
tlab_0.length = ret_2<<ret_2>>32
sp_0x10 = tlab_0
ret_28 = ?java.lang.StringConcatHelper.prepend(tlab_0, " ", ret_2)
ret_29 = java.lang.StringConcatHelper.prepend(ret_28, sp_0x10, 0)
ret_30 = ?java.lang.StringConcatHelper.newString(sp_0x10, ret_29)
java.io.PrintStream.write(sp_0x20, ret_30)
In unserem Java-Code wird die einfache String-Verkettungsoperation tatsächlich in drei Funktionsaufrufe umgewandelt: StringConcatHelper.mix, StringConcatHelper.prepend und StringConcatHelper.newString. Dabei berechnet StringConcatHelper.mix die Länge des verketteten Strings, StringConcatHelper.prepend fügt die byte[]-Arrays zusammen, die den spezifischen String-Inhalt tragen, und StringConcatHelper.newString generiert ein neues String-Objekt aus dem byte[]-Array.
Im obigen Code sehen wir zwei Arten von Variablennamen: sp_0x18 und tlab_0. Variablen, die mit sp_ beginnen, bezeichnen auf dem Stack allokierte Variablen, während Variablen, die mit tlab_ beginnen, auf Thread Local Allocation Buffers allokierte Variablen bezeichnen. Dies ist nur eine Erklärung der Herkunft dieser beiden Arten von Variablennamen. Im wiederhergestellten Code gibt es keine Unterscheidung zwischen diesen beiden Variablentypen. Informationen zu Thread Local Allocation Buffers suchen Sie bitte selbst.
Hier weisen wir tlab_0 zu Class{[B}_1 zu. Die Bedeutung von Class{[B}_1 ist eine Instanz des byte[]-Typs. [B repräsentiert den Java-Deskriptor für byte[], _1 gibt an, dass es die erste Variable dieses Typs ist. Wenn es nachfolgende Variablen des entsprechenden Typs gibt, wird der Index entsprechend erhöht, wie Class{[B]}_2, Class{[B]}_3 usw. Die gleiche Darstellung gilt für andere Typen, wie Class{java.lang.String}_1, Class{java.util.HashMap}_2 und so weiter.
Die Logik des obigen Codes erklärt das einfache Erstellen einer byte[]-Array-Instanz und die Zuweisung an tlab0. Die Länge des Arrays ist ret_2 << ret_2 >> 32. Der Grund, warum die Länge des Arrays ret_2 << ret_2 >> 32 ist, liegt darin, dass bei der Berechnung der Länge eines Strings die Länge des Arrays basierend auf der Kodierung umgerechnet werden muss. Sie können den relevanten Code in java.lang.String.java nachschlagen. Als nächstes fügt die prepend-Funktion 0, 1 und Leerzeichen in tlab0 zusammen, generiert dann ein neues String-Objekt ret_30 aus tlab_0 und übergibt es an die java.io.PrintStream.write-Funktion zur Druckausgabe. Tatsächlich sind hier die durch die prepend-Funktion wiederhergestellten Parameter nicht sehr genau und ihre Positionen sind ebenfalls inkorrekt. Dies ist ein Bereich, der in Zukunft weiter verbessert werden muss.
Nachdem die beiden Zeilen Java-Code in die tatsächliche Ausführungslogik umgewandelt wurden, ist es immer noch recht komplex. In Zukunft kann es durch Analyse und Integration auf Basis des derzeit wiederhergestellten Codes vereinfacht werden.
Weiter geht's
for (int i = 2; i < count; ++i){
n3 = n1 + n2;
System.out.print(" " + n3);
n1 = n2;
n2 = n3;
}
System.out.println();
Dies entspricht
if(sp_0x44>=3)
{
ret_7 = java.lang.StringConcatHelper.mix(1, 1)
tlab_1 = sp_0x18
tlab_1.length = ret_7<<ret_7>>32
sp_0x10 = " "
sp_0x8 = tlab_1
ret_22 = ?java.lang.StringConcatHelper.prepend(tlab_1, " ", ret_7)
ret_23 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_22)
rsi = ret_23
java.io.PrintStream.write(sp_0x20, ret_23)
rdi = 1
rdx = 1
rcx = 3
while(true)
{
if(sp_0x44<=rcx)
{
break
}
else
{
sp_0x34 = rcx
rdi = rdi+rdx
r9 = rdi
sp_0x30 = rdx
sp_0x2c = r9
ret_11 = java.lang.StringConcatHelper.mix(1, r9)
tlab_2 = sp_0x18
tlab_2.length = ret_11<<ret_11>>32
sp_0x8 = tlab_2
ret_17 = ?java.lang.StringConcatHelper.prepend(tlab_2, sp_0x10, ret_11)
ret_18 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_17)
rsi = ret_18
java.io.PrintStream.write(sp_0x20, ret_18)
rcx = sp_0x34+1
rdi = sp_0x30
rdx = sp_0x2c
}
}
}
java.io.PrintStream.newLine(sp_0x20, rsi)
return
sp_0x44 ist der Parameter, den wir dem Programm eingeben, also count. Die for-Schleife im Java-Code wird nur ausgeführt, wenn count >= 3. Hier wird die for-Schleife zurück in eine while-Schleife transformiert, die im Wesentlichen dieselbe Semantik hat. Außerhalb der while-Schleife führt das Programm die Logik für count=3 aus. Wenn count <= 3, beendet das Programm die Ausführung und wird die while-Schleife nicht erneut betreten. Dies könnte auch eine Optimierung sein, die GraalVM während der Kompilierung durchführt.
Schauen wir uns die Austrittsbedingung der Schleife erneut an.
if(sp_0x44<=rcx)
{
break
}
Dies entspricht
i < count
Gleichzeitig wird rcx bei jedem Iterationsprozess auch akkumuliert.
sp_0x34 = rcx
rcx = sp_0x34+1
entspricht
++i
Als nächstes schauen wir uns an, wie die Logik der Zahlenaddition im Schleifenkörper im wiederhergestellten Code widergespiegelt wird. Der Originalcode lautet wie folgt:
for(......){
......
n3 = n1 + n2;
n1 = n2;
n2 = n3;
......
}
Der wiederhergestellte Code lautet
while(true){
......
rdi = rdi+rdx -> n3 = n1 + n2
r9 = rdi -> r9 = n3
sp_0x30 = rdx -> sp_0x30 = n2
sp_0x2c = r9 -> sp_0x2c = n3
rdi = sp_0x30 -> n1 = sp_0x30 = n2
rdx = sp_0x2c -> n2 = sp_0x2c = n3
......
}
Der andere Code im Schleifenkörper führt wie zuvor String-Verkettungs- und Ausgabeoperationen durch. Der wiederhergestellte Code spiegelt im Wesentlichen die Ausführungslogik des Originalcodes wider.
Weitere Verbesserungen sind nötig
Derzeit kann dieses Tool den Programmkontrollfluss teilweise wiederherstellen und ein gewisses Maß an Datenflussanalyse und Funktionsnamen-Wiederherstellung erreichen. Um ein vollständiges und nutzbares Tool zu werden, muss es noch Folgendes erreichen:
Genauere Wiederherstellung von Funktionsnamen, Funktionsparametern und Funktionsrückgabewerten
Genaue Wiederherstellung von Objektinformationen und Feldern
Genauere Ausdrucks- und Objekttyp-Inferenz
Anweisungsintegration und -vereinfachung
Gedanken zum binären Schutz
Der Zweck dieses Projekts ist es, die Machbarkeit des Reverse Engineering von NativeImage zu untersuchen. Basierend auf den aktuellen Ergebnissen ist es machbar, NativeImage zurückzuentwickeln, was auch höhere Herausforderungen an den Code-Schutz stellt. Viele Entwickler glauben, dass das Kompilieren von Software in Binärdateien Sicherheit garantieren kann, und vernachlässigen den Schutz des Binärcodes. Für in C/C++ geschriebene Software haben bereits viele Tools wie IDA hervorragende Reverse-Engineering-Ergebnisse, die manchmal sogar mehr Informationen offenlegen als Java-Programme. Ich habe sogar Software gesehen, die in binärer Form verteilt wird, ohne die Symbolinformationen der Funktionsnamen zu entfernen, was gleichbedeutend damit ist, ungeschützt zu laufen.
Jeder Code besteht aus Logik. Solange er Logik enthält, ist es möglich, seine Logik durch Reverse-Engineering-Methoden wiederherzustellen. Der einzige Unterschied liegt in der Schwierigkeit der Wiederherstellung. Code-Schutz zielt darauf ab, die Schwierigkeit einer solchen Wiederherstellung zu maximieren.