Ingeniería Inversa de NativeImage
Restaurar y proteger código Java es un tema antiguo y frecuentemente discutido. Debido al formato de bytecode utilizado para almacenar archivos class de Java, que contiene mucha meta-información, puede restaurarse fácilmente a su código original. Para proteger el código Java, la industria ha adoptado muchos métodos, como ofuscación, cifrado de bytecode, protección JNI, etc. Sin embargo, independientemente del método utilizado, aún existen formas y medios para crackearlo.
La compilación binaria siempre se ha considerado como un método relativamente efectivo de protección de código. La compilación binaria de Java se admite como tecnología AOT (Ahead of Time), que significa precompilación.
Sin embargo, debido a la naturaleza dinámica del lenguaje Java, la compilación binaria necesita manejar problemas como reflexión, proxy dinámico, carga JNI, etc., lo que plantea muchas dificultades. Por lo tanto, durante mucho tiempo, ha habido una falta de una herramienta madura, confiable y adaptable para la compilación AOT en Java que pueda aplicarse ampliamente en entornos de producción. (Solía existir una herramienta llamada Excelsior JET, pero parece haber sido descontinuada ahora.)
En mayo de 2019, Oracle lanzó GraalVM 19.0, una máquina virtual con soporte multilenguaje, que fue su primera versión lista para producción. GraalVM proporciona una herramienta NativeImage que puede lograr la compilación AOT de programas Java. Después de varios años de desarrollo, NativeImage es ahora muy maduro, y SpringBoot 3.0 puede usarlo para compilar todo el proyecto SpringBoot en un archivo ejecutable. El archivo compilado tiene una velocidad de inicio rápida, bajo uso de memoria y excelente rendimiento.
Entonces, para los programas Java que han entrado en la era de la compilación binaria, ¿su código aún es tan fácilmente reversible como en la era del bytecode? ¿Cuáles son las características de los archivos binarios compilados por NativeImage, y es la intensidad de la compilación binaria suficiente para proteger código importante?
Para explorar estos problemas, recientemente desarrollamos una herramienta de análisis de NativeImage, que ha logrado un cierto grado de efecto de ingeniería inversa.
Proyecto
https://github.com/vlinx-io/NativeImageAnalyzer
Generación de NativeImage
Primero, necesitamos generar un NativeImage. NativeImage proviene de GraalVM. Para descargar GraalVM, vaya a https://www.graalvm.org/ y descargue la versión para Java 17. Después de descargar, configure la variable de entorno. Dado que GraalVM contiene un JDK, puede usarlo directamente para ejecutar el comando java.
Agregue $GRAALVM_HOME/bin a la variable de entorno, y luego ejecute el siguiente comando para instalar la herramienta native-image
gu install native-image
Un programa Java simple
Escriba un programa Java simple, por ejemplo:
public class Hello {
public static void main(String[] args){
System.out.println("Hello World!");
}
}
Compile y ejecute el programa Java anterior:
javac Hello.java
java -cp . Hello
Obtendrá la siguiente salida:
Hello World!
Preparación del Entorno de Compilación
Si es usuario de Windows, necesita instalar Visual Studio primero. Si es usuario de Linux o macOS, necesita instalar herramientas como gcc y clang de antemano.
Para usuarios de Windows, necesita configurar la variable de entorno de Visual Studio antes de ejecutar el comando native-image. Puede configurarlo usando el siguiente comando:
"C:\Program Files (x86)\Microsoft Visual Studio\2017\Community\VC\Auxiliary\Build\vcvars64.bat"
Si la ruta de instalación y la versión de Visual Studio son diferentes, ajuste la información de la ruta en consecuencia.
Compilar con native-image
Ahora use el comando native-image para compilar el programa Java anterior en un archivo binario. El formato del comando native-image es el mismo que el formato del comando java, y también tiene los parámetros -cp, -jar. Cómo usar el comando java para ejecutar el programa, use el mismo método para la compilación binaria, simplemente reemplace el comando de java por native-image. Ejecute el comando de la siguiente manera
native-image -cp . Hello
Después de un período de compilación, puede consumir más CPU y memoria. Puede obtener un archivo binario compilado, y el nombre del archivo de salida es por defecto el nombre en minúsculas de la clase principal, que es "hello" en este caso. Si está en Windows, será "hello.exe". Use el comando "file" para verificar el tipo de este archivo, puede ver que es efectivamente un archivo binario.
file hello
hello: Mach-O 64-bit executable x86_64
Ejecute este archivo, y su salida será la misma que la obtenida anteriormente al usar java -cp . Hello. El resultado es consistente
Hello World!
Análisis de NativeImage
Análisis con IDA
Use IDA para abrir el hello compilado de los pasos anteriores, haga clic en Exports para ver la tabla de símbolos, puede ver el símbolo svm_code_section, y su dirección es la dirección de entrada de la función Java Main.
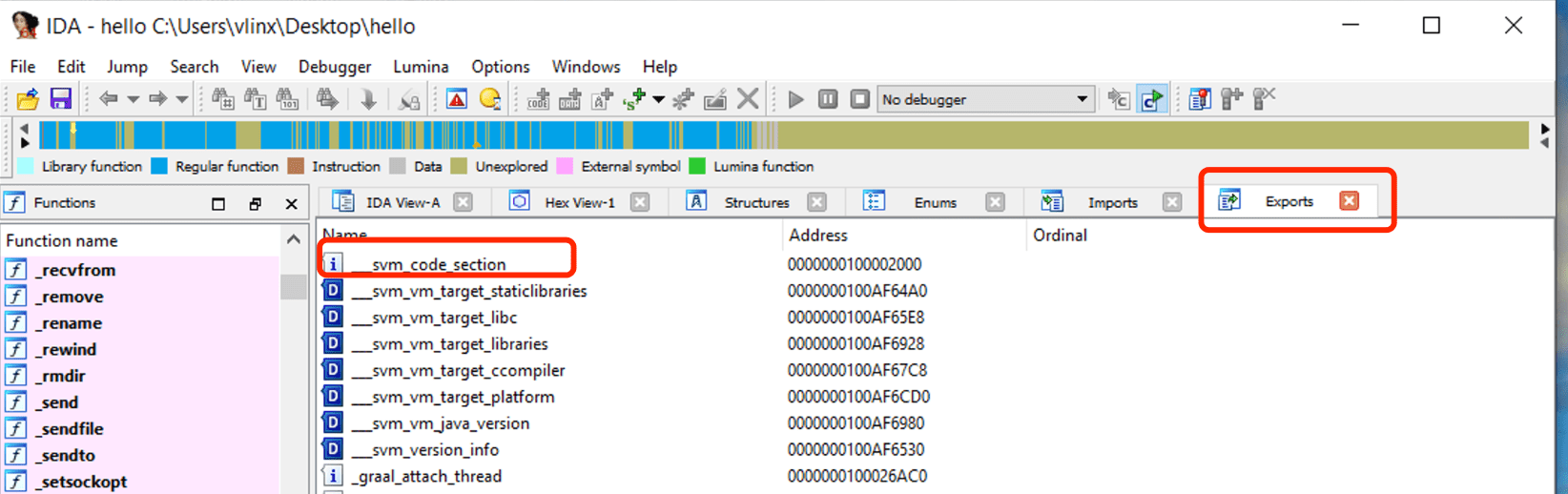
Navegue a esta dirección para ver el código ensamblador
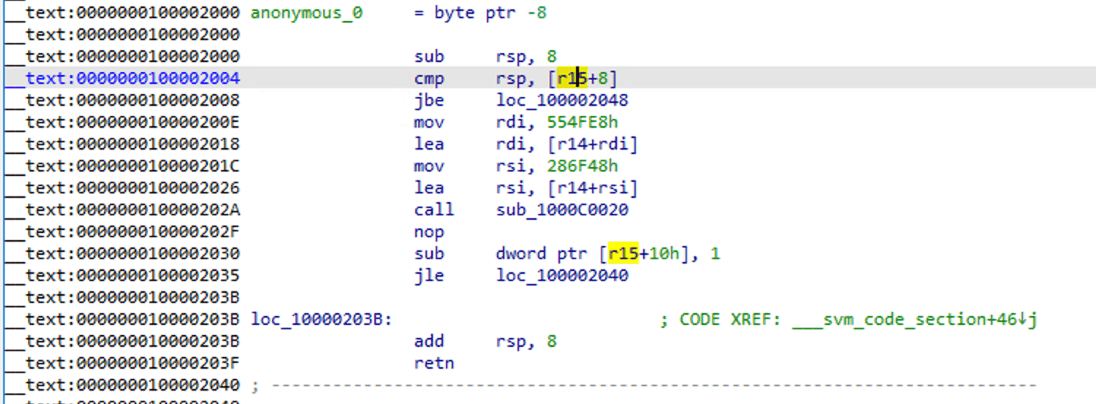
Puede ver que se ha convertido en una función ensamblador estándar, use F5 para decompilar
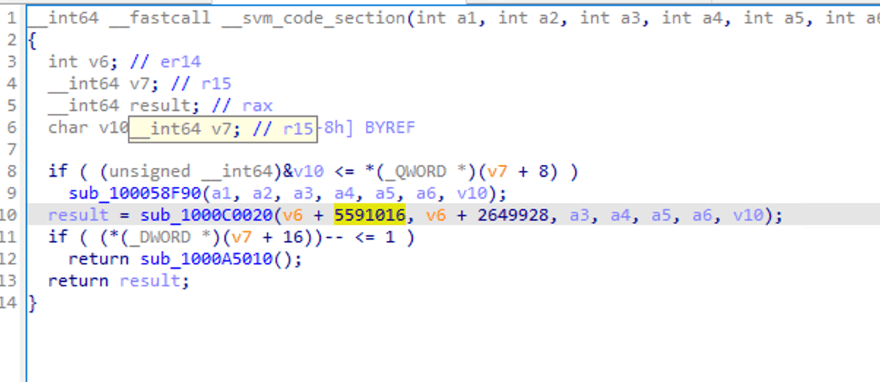
Se pueden ver algunas llamadas a funciones, y se pasan algunos parámetros, pero no es fácil ver la lógica.
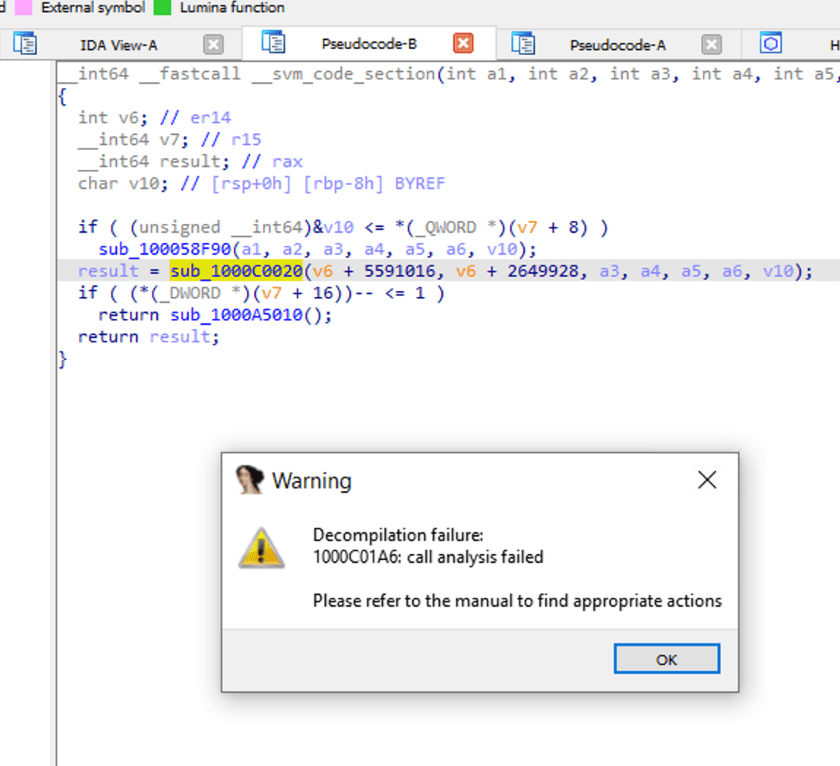
Cuando hacemos doble clic en sub_1000C0020, veamos dentro de la llamada a función. IDA indica fallo en el análisis.
Lógica de Decompilación de NativeImage
Debido a que la compilación de NativeImage se basa en la compilación JVM, también puede entenderse como encerrar código binario con una capa de protección VM. Por lo tanto, herramientas como IDA no pueden realizar ingeniería inversa de manera efectiva en ausencia de información correspondiente y medidas de procesamiento dirigidas.
Sin embargo, independientemente del formato, ya sea bytecode o forma binaria, algunos elementos básicos de la ejecución JVM están destinados a existir, como información de clases, información de campos, invocación de funciones y paso de parámetros. Basándose en esta mentalidad, la herramienta de análisis que he desarrollado puede lograr un cierto nivel de efecto de restauración y, con mejoras adicionales, tener la capacidad de lograr un alto nivel de precisión de restauración.
Análisis con NativeImageAnalyzer
Visite https://github.com/vlinx-io/NativeImageAnalyzer para descargar NativeImageAnalyzer
Ejecute el siguiente comando para el análisis inverso, actualmente solo analizando la función Main de la clase principal
native-image-analyzer hello
La salida es la siguiente
java.io.PrintStream.writeln(java.io.PrintStream@0x554fe8, "Hello World!", rcx)
return
Veamos el código original de nuevo.
public static void main(String[] args){
System.out.println("Hello World!");
}
Ahora veamos la definición de System.out.
public static final PrintStream out = null;
Puede ver que la variable 'out' de la clase System es una variable de tipo PrintStream, y es una variable estática. Durante la compilación, NativeImage compila directamente una instancia de esta clase en una región llamada Heap, y el código binario recupera directamente esta instancia de la región Heap para la invocación. Veamos el código original después de la restauración.
java.io.PrintStream.writeln(java.io.PrintStream@0x554fe8, "Hello World!", rcx)
return
Estos java.io.PrintStream@0x554fe8 es simplemente la variable de instancia java.io.PrintStream leída del área Heap, ubicada en la dirección de memoria 0x554fe8.
Veamos ahora la definición de la función java.io.PrintStream.writeln
private void writeln(String s) {
......
}
Aquí podemos ver que hay un argumento String en la función writeln, pero en el código restaurado, ¿por qué se pasan tres argumentos? Primero, writeln es un método miembro de clase que oculta solo un this, la variable apunta al llamador, que es el primer parámetro pasado, java.io.PrintStream@0x554fe8. En cuanto al tercer parámetro rcx, es porque durante el proceso de análisis del código ensamblador, se determinó que esta función fue llamada con tres parámetros. Sin embargo, al examinar la definición, sabemos que esta función en realidad solo llama con dos parámetros. Esta es también un área que necesita mejora para esta herramienta en el futuro.
Un programa más complejo
Ahora analizaremos un programa más complejo, como calcular una secuencia de Fibonacci, con el siguiente código
class Fibonacci {
public static void main(String[] args) {
int count = Integer.parseInt(args[0]);
int n1 = 0, n2 = 1, n3;
System.out.print(n1 + " " + n2);
for (int i = 2; i < count; ++i){
n3 = n1 + n2;
System.out.print(" " + n3);
n1 = n2;
n2 = n3;
}
System.out.println();
}
}
Compilar y ejecutar
javac Fibonacci.java
native-image -cp . Fibonacci
./fibonacci 10
0 1 1 2 3 5 8 13 21 34
El código obtenido después de la restauración usando NativeImageAnalyzer es el siguiente
rdi = rdi[0]
ret_0 = java.lang.Integer.parseInt(rdi, 10)
sp_0x44 = ret_0
ret_1 = java.lang.StringConcatHelper.mix(1, 1)
ret_2 = java.lang.StringConcatHelper.mix(ret_1, 0)
sp_0x20 = java.io.PrintStream@0x554fe8
sp_0x18 = Class{[B}_1
tlab_0 = Class{[B}_1
tlab_0.length = ret_2<<ret_2>>32
sp_0x10 = tlab_0
ret_28 = ?java.lang.StringConcatHelper.prepend(tlab_0, " ", ret_2)
ret_29 = java.lang.StringConcatHelper.prepend(ret_28, sp_0x10, 0)
ret_30 = ?java.lang.StringConcatHelper.newString(sp_0x10, ret_29)
java.io.PrintStream.write(sp_0x20, ret_30)
if(sp_0x44>=3)
{
ret_7 = java.lang.StringConcatHelper.mix(1, 1)
tlab_1 = sp_0x18
tlab_1.length = ret_7<<ret_7>>32
sp_0x10 = " "
sp_0x8 = tlab_1
ret_22 = ?java.lang.StringConcatHelper.prepend(tlab_1, " ", ret_7)
ret_23 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_22)
rsi = ret_23
java.io.PrintStream.write(sp_0x20, ret_23)
rdi = 1
rdx = 1
rcx = 3
while(true)
{
if(sp_0x44<=rcx)
{
break
}
else
{
sp_0x34 = rcx
rdi = rdi+rdx
r9 = rdi
sp_0x30 = rdx
sp_0x2c = r9
ret_11 = java.lang.StringConcatHelper.mix(1, r9)
tlab_2 = sp_0x18
tlab_2.length = ret_11<<ret_11>>32
sp_0x8 = tlab_2
ret_17 = ?java.lang.StringConcatHelper.prepend(tlab_2, sp_0x10, ret_11)
ret_18 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_17)
rsi = ret_18
java.io.PrintStream.write(sp_0x20, ret_18)
rcx = sp_0x34+1
rdi = sp_0x30
rdx = sp_0x2c
}
}
}
java.io.PrintStream.newLine(sp_0x20, rsi)
return
Compare el código restaurado con el código original.
rdi = rdi[0]
ret_0 = java.lang.Integer.parseInt(rdi, 10)
sp_0x44 = ret_0
Lo correspondiente es
int count = Integer.parseInt(args[0]);
rdi es el registro utilizado para pasar el primer argumento de una función, si es Windows, entonces rdi = rdi[0], que corresponde a args[0]. Después, se llama a java.lang.Integer.parseInt para analizar y obtener un valor int, luego se asigna el valor de retorno a una variable de pila sp_0x44.
int n1 = 0, n2 = 1, n3;
System.out.print(n1 + " " + n2);
Corresponde a
ret_1 = java.lang.StringConcatHelper.mix(1, 1)
ret_2 = java.lang.StringConcatHelper.mix(ret_1, 0)
sp_0x20 = java.io.PrintStream@0x554fe8
sp_0x18 = Class{[B}_1
tlab_0 = Class{[B}_1
tlab_0.length = ret_2<<ret_2>>32
sp_0x10 = tlab_0
ret_28 = ?java.lang.StringConcatHelper.prepend(tlab_0, " ", ret_2)
ret_29 = java.lang.StringConcatHelper.prepend(ret_28, sp_0x10, 0)
ret_30 = ?java.lang.StringConcatHelper.newString(sp_0x10, ret_29)
java.io.PrintStream.write(sp_0x20, ret_30)
En nuestro código Java, la simple operación de concatenación de cadenas se convierte en realidad en tres llamadas a funciones: StringConcatHelper.mix, StringConcatHelper.prepend y StringConcatHelper.newString. Entre ellas, StringConcatHelper.mix calcula la longitud de la cadena concatenada, StringConcatHelper.prepend combina el array byte[] que lleva el contenido específico de la cadena, y StringConcatHelper.newString genera un nuevo objeto String a partir del array byte[].
En el código anterior, vemos dos tipos de nombres de variables, sp_0x18 y tlab_0. Las variables que comienzan con sp_ indican variables asignadas en la pila, mientras que las variables que comienzan con tlab_ indican variables asignadas en Thread Local Allocation Buffers. Esto es solo una explicación del origen de estos dos tipos de nombres de variables. En el código restaurado, no hay distinción entre estos dos tipos de variables. Para información relacionada con Thread Local Allocation Buffers, búsquela por su cuenta.
Aquí asignamos tlab_0 a Class{[B}_1. El significado de Class{[B}_1 es una instancia del tipo byte[]. [B representa el descriptor Java para byte[], _1 indica que es la primera variable de este tipo. Si hay variables posteriores definidas para el tipo correspondiente, el índice aumentará en consecuencia, como Class{[B]}_2, Class{[B]}_3, etc. La misma representación se aplica a otros tipos, como Class{java.lang.String}_1, Class{java.util.HashMap}_2, etc.
La lógica del código anterior se explica simplemente creando una instancia de array byte[] y asignándola a tlab0. La longitud del array es ret_2 << ret_2 >> 32. La razón por la cual la longitud del array es ret_2 << ret_2 >> 32 es porque al calcular la longitud de un String, necesita convertir la longitud del array según la codificación. Puede consultar el código relevante en java.lang.String.java. A continuación, la función prepend combina 0, 1 y espacios en tlab0, luego genera un nuevo objeto String ret_30 a partir de tlab_0 y lo pasa a la función java.io.PrintStream.write para la salida de impresión. En realidad, aquí los parámetros restaurados por la función prepend no son muy precisos y sus posiciones también son incorrectas. Esta es un área que necesita más mejora posteriormente.
Después de convertir las dos líneas de código Java en lógica de ejecución real, sigue siendo bastante complejo. En el futuro, puede simplificarse analizando e integrando sobre la base del código actualmente restaurado.
Continuando hacia adelante
for (int i = 2; i < count; ++i){
n3 = n1 + n2;
System.out.print(" " + n3);
n1 = n2;
n2 = n3;
}
System.out.println();
Lo correspondiente es
if(sp_0x44>=3)
{
ret_7 = java.lang.StringConcatHelper.mix(1, 1)
tlab_1 = sp_0x18
tlab_1.length = ret_7<<ret_7>>32
sp_0x10 = " "
sp_0x8 = tlab_1
ret_22 = ?java.lang.StringConcatHelper.prepend(tlab_1, " ", ret_7)
ret_23 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_22)
rsi = ret_23
java.io.PrintStream.write(sp_0x20, ret_23)
rdi = 1
rdx = 1
rcx = 3
while(true)
{
if(sp_0x44<=rcx)
{
break
}
else
{
sp_0x34 = rcx
rdi = rdi+rdx
r9 = rdi
sp_0x30 = rdx
sp_0x2c = r9
ret_11 = java.lang.StringConcatHelper.mix(1, r9)
tlab_2 = sp_0x18
tlab_2.length = ret_11<<ret_11>>32
sp_0x8 = tlab_2
ret_17 = ?java.lang.StringConcatHelper.prepend(tlab_2, sp_0x10, ret_11)
ret_18 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_17)
rsi = ret_18
java.io.PrintStream.write(sp_0x20, ret_18)
rcx = sp_0x34+1
rdi = sp_0x30
rdx = sp_0x2c
}
}
}
java.io.PrintStream.newLine(sp_0x20, rsi)
return
sp_0x44 es el parámetro que ingresamos al programa, que es count. El bucle for en el código Java solo se ejecutará si count >= 3. Aquí, el bucle for se transforma de nuevo en un bucle while, teniendo esencialmente la misma semántica. Fuera del bucle while, el programa ejecuta la lógica donde count=3. Si count <= 3, el programa completa la ejecución y no entrará en el bucle while de nuevo. Esto también puede ser una optimización hecha por GraalVM durante la compilación.
Veamos la condición de salida del bucle de nuevo.
if(sp_0x44<=rcx)
{
break
}
Esto corresponde a
i < count
Al mismo tiempo, rcx también se acumula durante cada proceso de iteración.
sp_0x34 = rcx
rcx = sp_0x34+1
corresponde a
++i
A continuación, veamos cómo la lógica de adición de números en el cuerpo del bucle se refleja en el código restaurado. El código original es el siguiente:
for(......){
......
n3 = n1 + n2;
n1 = n2;
n2 = n3;
......
}
El código después de la restauración es
while(true){
......
rdi = rdi+rdx -> n3 = n1 + n2
r9 = rdi -> r9 = n3
sp_0x30 = rdx -> sp_0x30 = n2
sp_0x2c = r9 -> sp_0x2c = n3
rdi = sp_0x30 -> n1 = sp_0x30 = n2
rdx = sp_0x2c -> n2 = sp_0x2c = n3
......
}
El otro código en el cuerpo del bucle realiza operaciones de concatenación de cadenas y salida como antes. El código restaurado refleja básicamente la lógica de ejecución del código original.
Se necesitan más mejoras
Actualmente, esta herramienta es capaz de restaurar parcialmente el flujo de control del programa, lograr cierto nivel de análisis de flujo de datos y restauración de nombres de funciones. Para convertirse en una herramienta completa y usable, aún necesita lograr lo siguiente:
Restauración más precisa de nombres de funciones, parámetros de funciones y valores de retorno de funciones
Restauración precisa de información de objetos y campos
Inferencia más precisa de expresiones y tipos de objetos
Integración y Simplificación de Declaraciones
Reflexiones sobre la protección binaria
El propósito de este proyecto es explorar la viabilidad de la ingeniería inversa de NativeImage. Basándose en los logros actuales, es factible realizar ingeniería inversa de NativeImage, lo que también trae mayores desafíos para la protección de código. Muchos desarrolladores creen que compilar software en binarios puede garantizar la seguridad, descuidando la protección del código binario. Para software escrito en C/C++, muchas herramientas como IDA ya tienen excelentes efectos de ingeniería inversa, a veces exponiendo incluso más información que los programas Java. Incluso he visto algunos software distribuidos en forma binaria sin eliminar la información de símbolos de nombres de funciones, lo cual es equivalente a funcionar sin protección.
Cualquier código está compuesto de lógica. Mientras contenga lógica, es posible restaurar su lógica mediante medios inversos. La única diferencia radica en la dificultad de la restauración. La protección de código es maximizar la dificultad de dicha restauración.