NativeImageリバースエンジニアリング
Javaコードの復元と保護は古くからよく議論されているテーマです。Javaクラスファイルの保存に使用されるバイトコード形式には多くのメタ情報が含まれているため、元のコードに容易に復元できます。Javaコードを保護するために、業界では難読化、バイトコード暗号化、JNI保護など多くの方法が採用されてきました。しかし、どの方法を使用しても、クラッキングする方法と手段は依然として存在します。
バイナリコンパイルは常にコード保護の比較的効果的な方法と考えられてきました。JavaのバイナリコンパイルはAOT(Ahead of Time)技術としてサポートされており、事前コンパイルを意味します。
しかし、Java言語の動的な性質のため、バイナリコンパイルはリフレクション、動的プロキシ、JNIロードなどの問題を処理する必要があり、多くの困難をもたらします。そのため、長い間、Javaには本番環境で広く適用できる成熟した信頼性の高いAOTコンパイルツールがありませんでした。(かつてExcelsior JETというツールがありましたが、現在は廃止されたようです。)
2019年5月、Oracleは複数言語をサポートする仮想マシンGraalVM 19.0をリリースしました。これは最初のプロダクションレディバージョンでした。GraalVMはJavaプログラムのAOTコンパイルを実現できるNativeImageツールを提供しています。数年の開発を経て、NativeImageは現在非常に成熟しており、SpringBoot 3.0はこれを使用してSpringBootプロジェクト全体を実行ファイルにコンパイルできます。コンパイルされたファイルは起動速度が速く、メモリ使用量が少なく、優れたパフォーマンスを発揮します。
では、バイナリコンパイルの時代に入ったJavaプログラムのコードは、バイトコード時代と同様に簡単にリバースできるのでしょうか?NativeImageでコンパイルされたバイナリファイルにはどのような特徴があり、バイナリコンパイルの強度は重要なコードを保護するのに十分でしょうか?
これらの問題を探るために、最近NativeImage分析ツールを開発し、一定程度のリバース効果を達成しました。
プロジェクト
https://github.com/vlinx-io/NativeImageAnalyzer
NativeImageの生成
まず、NativeImageを生成する必要があります。NativeImageはGraalVMに含まれています。GraalVMをダウンロードするには、https://www.graalvm.org/ にアクセスしてJava 17用のバージョンをダウンロードしてください。ダウンロード後、環境変数を設定します。GraalVMにはJDKが含まれているため、直接javaコマンドを実行できます。
$GRAALVM_HOME/binを環境変数に追加し、以下のコマンドを実行してnative-imageツールをインストールしてください。
gu install native-image
シンプルなJavaプログラム
シンプルなJavaプログラムを作成します。例えば:
public class Hello {
public static void main(String[] args){
System.out.println("Hello World!");
}
}
上記のJavaプログラムをコンパイルして実行します:
javac Hello.java
java -cp . Hello
以下の出力が得られます:
Hello World!
コンパイル環境の準備
Windowsユーザーの場合は、まずVisual Studioをインストールする必要があります。LinuxまたはmacOSユーザーの場合は、gccやclangなどのツールを事前にインストールする必要があります。
Windowsユーザーの場合は、native-imageコマンドを実行する前にVisual Studioの環境変数を設定する必要があります。以下のコマンドで設定できます:
"C:\Program Files (x86)\Microsoft Visual Studio\2017\Community\VC\Auxiliary\Build\vcvars64.bat"
Visual Studioのインストールパスとバージョンが異なる場合は、関連するパス情報を適宜調整してください。
native-imageでコンパイル
次にnative-imageコマンドを使用して上記のJavaプログラムをバイナリファイルにコンパイルします。native-imageコマンドの形式はjavaコマンドの形式と同じで、-cp、-jarなどのパラメータがあります。javaコマンドでプログラムを実行するのと同じ方法でバイナリコンパイルを行い、コマンドをjavaからnative-imageに置き換えるだけです。以下のコマンドを実行してください:
native-image -cp . Hello
一定時間のコンパイル後(CPUとメモリをより多く消費する場合があります)、コンパイルされたバイナリファイルが得られます。出力ファイル名はデフォルトでメインクラスの小文字(この場合は「hello」)になります。Windowsの場合は「hello.exe」になります。「file」コマンドでこのファイルのタイプを確認すると、確かにバイナリファイルであることがわかります。
file hello
hello: Mach-O 64-bit executable x86_64
このファイルを実行すると、前にjava -cp . Helloで得た結果と同じ出力が得られます。
Hello World!
NativeImageの分析
IDAでの分析
IDAを使用して上記の手順でコンパイルされたhelloを開き、Exportsをクリックしてシンボルテーブルを表示すると、シンボルsvm_code_sectionが表示されます。そのアドレスはJava Main関数のエントリアドレスです。
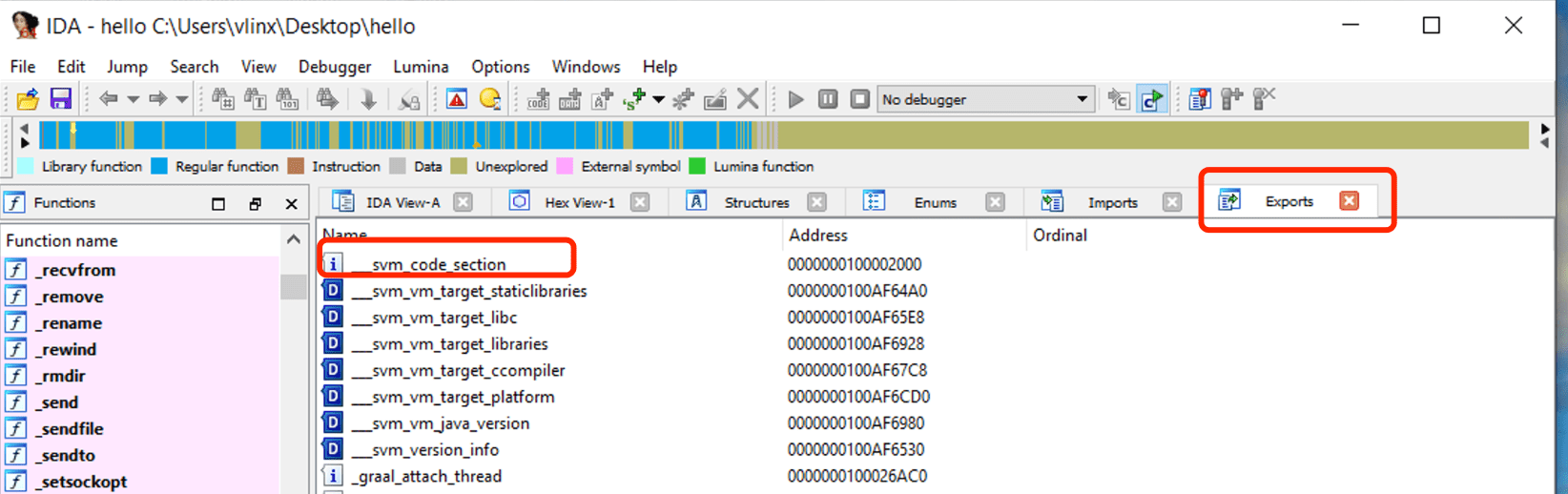
このアドレスに移動してアセンブリコードを表示します。
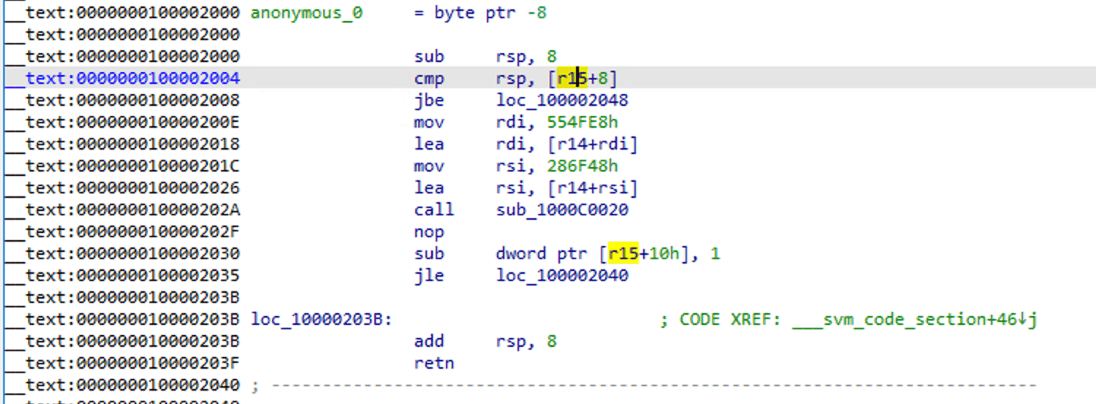
標準的なアセンブリ関数になっていることがわかります。F5を使用して逆コンパイルします。
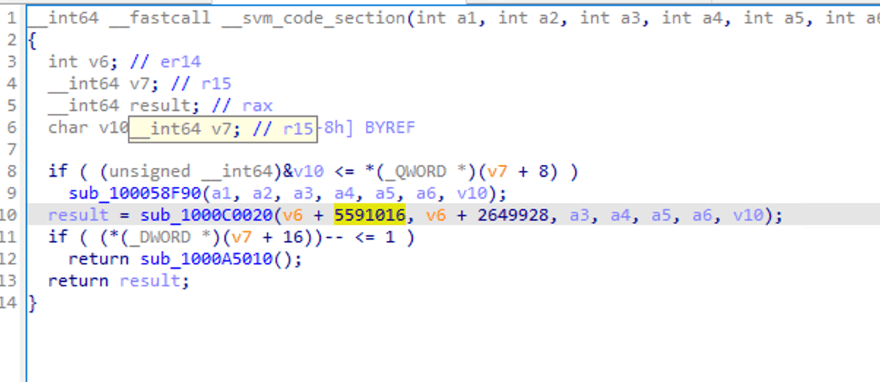
いくつかの関数呼び出しとパラメータの受け渡しが確認できますが、ロジックを理解するのは容易ではありません。
sub_1000C0020をダブルクリックして関数呼び出し内部を見ると、IDAは分析失敗を示します。
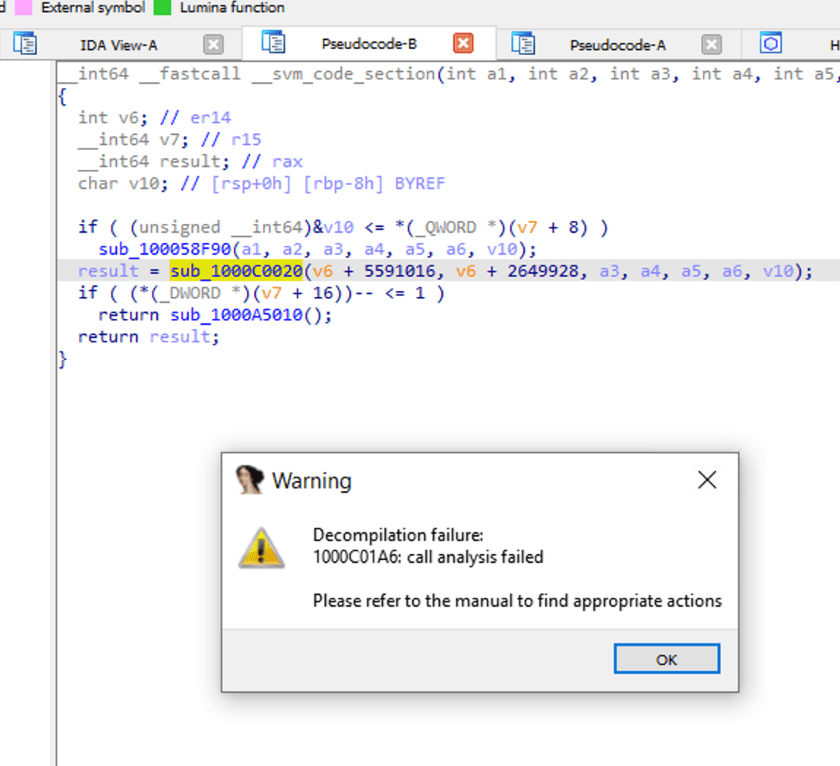
NativeImageの逆コンパイルロジック
NativeImageのコンパイルはJVMのコンパイルに基づいているため、バイナリコードをVM保護の層で囲んでいると理解することもできます。そのため、対応する情報や対象を絞った処理がない場合、IDAなどのツールではうまくリバースエンジニアリングすることができません。
しかし、バイトコードであろうとバイナリ形式であろうと、クラス情報、フィールド情報、関数呼び出し、パラメータ受け渡しなど、JVM実行のいくつかの基本要素は必ず存在します。この考え方に基づいて、開発した分析ツールは一定レベルの復元効果を達成し、さらなる改善により高い復元精度を実現する能力を持っています。
NativeImageAnalyzerでの分析
https://github.com/vlinx-io/NativeImageAnalyzer にアクセスしてNativeImageAnalyzerをダウンロードしてください。
以下のコマンドでリバース分析を実行します。現在はメインクラスのMain関数のみを分析しています。
native-image-analyzer hello
出力は以下の通りです:
java.io.PrintStream.writeln(java.io.PrintStream@0x554fe8, "Hello World!", rcx)
return
元のコードを再度確認しましょう。
public static void main(String[] args){
System.out.println("Hello World!");
}
次にSystem.outの定義を確認しましょう。
public static final PrintStream out = null;
SystemクラスのoutはPrintStream型の変数で、静的変数であることがわかります。コンパイル時に、NativeImageはこのクラスのインスタンスをHeapと呼ばれる領域に直接コンパイルし、バイナリコードはこのHeap領域からインスタンスを直接取得して呼び出します。復元後のコードを確認しましょう。
java.io.PrintStream.writeln(java.io.PrintStream@0x554fe8, "Hello World!", rcx)
return
このjava.io.PrintStream@0x554fe8はHeap領域から読み取られたjava.io.PrintStreamのインスタンス変数で、メモリアドレス0x554fe8にあります。
次にjava.io.PrintStream.writeln関数の定義を見てみましょう。
private void writeln(String s) {
......
}
ここでwriteln関数にはString引数が1つありますが、復元コードではなぜ3つの引数が渡されているのでしょうか?まずwritelnはクラスのメンバメソッドで、1つのthisを隠し持っています。この変数は呼び出し元を指し、最初のパラメータとして渡されているjava.io.PrintStream@0x554fe8です。3番目のパラメータrcxについては、アセンブリコードの分析過程でこの関数が3つのパラメータで呼び出されていると判定されたためです。しかし、定義を見ると、実際には2つのパラメータしか呼び出していないことがわかります。これは今後このツールが改善すべき領域でもあります。
より複雑なプログラム
次に、フィボナッチ数列の計算など、より複雑なプログラムを分析してみましょう。コードは以下の通りです:
class Fibonacci {
public static void main(String[] args) {
int count = Integer.parseInt(args[0]);
int n1 = 0, n2 = 1, n3;
System.out.print(n1 + " " + n2);
for (int i = 2; i < count; ++i){
n3 = n1 + n2;
System.out.print(" " + n3);
n1 = n2;
n2 = n3;
}
System.out.println();
}
}
コンパイルして実行します。
javac Fibonacci.java
native-image -cp . Fibonacci
./fibonacci 10
0 1 1 2 3 5 8 13 21 34
NativeImageAnalyzerで復元されたコードは以下の通りです:
rdi = rdi[0]
ret_0 = java.lang.Integer.parseInt(rdi, 10)
sp_0x44 = ret_0
ret_1 = java.lang.StringConcatHelper.mix(1, 1)
ret_2 = java.lang.StringConcatHelper.mix(ret_1, 0)
sp_0x20 = java.io.PrintStream@0x554fe8
sp_0x18 = Class{[B}_1
tlab_0 = Class{[B}_1
tlab_0.length = ret_2<<ret_2>>32
sp_0x10 = tlab_0
ret_28 = ?java.lang.StringConcatHelper.prepend(tlab_0, " ", ret_2)
ret_29 = java.lang.StringConcatHelper.prepend(ret_28, sp_0x10, 0)
ret_30 = ?java.lang.StringConcatHelper.newString(sp_0x10, ret_29)
java.io.PrintStream.write(sp_0x20, ret_30)
if(sp_0x44>=3)
{
ret_7 = java.lang.StringConcatHelper.mix(1, 1)
tlab_1 = sp_0x18
tlab_1.length = ret_7<<ret_7>>32
sp_0x10 = " "
sp_0x8 = tlab_1
ret_22 = ?java.lang.StringConcatHelper.prepend(tlab_1, " ", ret_7)
ret_23 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_22)
rsi = ret_23
java.io.PrintStream.write(sp_0x20, ret_23)
rdi = 1
rdx = 1
rcx = 3
while(true)
{
if(sp_0x44<=rcx)
{
break
}
else
{
sp_0x34 = rcx
rdi = rdi+rdx
r9 = rdi
sp_0x30 = rdx
sp_0x2c = r9
ret_11 = java.lang.StringConcatHelper.mix(1, r9)
tlab_2 = sp_0x18
tlab_2.length = ret_11<<ret_11>>32
sp_0x8 = tlab_2
ret_17 = ?java.lang.StringConcatHelper.prepend(tlab_2, sp_0x10, ret_11)
ret_18 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_17)
rsi = ret_18
java.io.PrintStream.write(sp_0x20, ret_18)
rcx = sp_0x34+1
rdi = sp_0x30
rdx = sp_0x2c
}
}
}
java.io.PrintStream.newLine(sp_0x20, rsi)
return
復元されたコードと元のコードを比較しましょう。
rdi = rdi[0]
ret_0 = java.lang.Integer.parseInt(rdi, 10)
sp_0x44 = ret_0
対応するのは
int count = Integer.parseInt(args[0]);
rdiは関数の最初の引数を渡すために使用されるレジスタです。Windowsの場合は、rdi = rdi[0]がargs[0]に対応します。その後、java.lang.Integer.parseIntを呼び出してint値を解析し取得し、戻り値をスタック変数sp_0x44に代入します。
int n1 = 0, n2 = 1, n3;
System.out.print(n1 + " " + n2);
対応するのは
ret_1 = java.lang.StringConcatHelper.mix(1, 1)
ret_2 = java.lang.StringConcatHelper.mix(ret_1, 0)
sp_0x20 = java.io.PrintStream@0x554fe8
sp_0x18 = Class{[B}_1
tlab_0 = Class{[B}_1
tlab_0.length = ret_2<<ret_2>>32
sp_0x10 = tlab_0
ret_28 = ?java.lang.StringConcatHelper.prepend(tlab_0, " ", ret_2)
ret_29 = java.lang.StringConcatHelper.prepend(ret_28, sp_0x10, 0)
ret_30 = ?java.lang.StringConcatHelper.newString(sp_0x10, ret_29)
java.io.PrintStream.write(sp_0x20, ret_30)
Javaコードに書かれたシンプルな文字列連結操作は、実際にはStringConcatHelper.mix、StringConcatHelper.prepend、StringConcatHelper.newStringの3つの関数呼び出しに変換されます。StringConcatHelper.mixは連結された文字列の長さを計算し、StringConcatHelper.prependは具体的な文字列内容を持つbyte[]配列を結合し、StringConcatHelper.newStringはbyte[]配列から新しいStringオブジェクトを生成します。
上のコードでは、sp_0x18とtlab_0の2種類の変数名が見られます。sp_で始まる変数はスタックに割り当てられた変数を示し、tlab_で始まる変数はThread Local Allocation Buffersに割り当てられた変数を示します。これは2種類の変数名の由来の説明に過ぎません。復元コードでは、この2種類の変数に区別はありません。Thread Local Allocation Buffersに関連する情報については、自身で検索してください。
ここでtlab_0をClass{[B}_1に代入しています。Class{[B}_1はbyte[]型のインスタンスを意味します。[Bはbyte[]のJavaディスクリプタを表し、_1はこの型の最初の変数であることを示します。対応する型の後続の変数定義がある場合、インデックスはClass{[B]}_2、Class{[B]}_3などのように増加します。他の型にも同じ表現が適用されます(例:Class{java.lang.String}_1、Class{java.util.HashMap}_2など)。
上記コードのロジックは単純にbyte[]配列インスタンスを作成してtlab0に代入することを説明しています。配列の長さはret_2 << ret_2 >> 32です。配列の長さがret_2 << ret_2 >> 32である理由は、Stringの長さを計算する際にエンコーディングに基づいて配列の長さを変換する必要があるためです。java.lang.String.javaの関連コードを参照してください。次に、prepend関数が0、1、スペースをtlab0に結合し、tlab_0から新しいStringオブジェクトret_30を生成してjava.io.PrintStream.write関数に渡して出力します。実際には、ここでprepend関数によって復元されたパラメータはあまり正確ではなく、位置も正しくありません。これは今後さらに改善が必要な領域です。
2行のJavaコードを実際の実行ロジックに変換すると、かなり複雑になります。今後、現在復元されたコードを基に分析・統合することで簡略化できるでしょう。
続けて見ていきましょう
for (int i = 2; i < count; ++i){
n3 = n1 + n2;
System.out.print(" " + n3);
n1 = n2;
n2 = n3;
}
System.out.println();
対応するのは
if(sp_0x44>=3)
{
ret_7 = java.lang.StringConcatHelper.mix(1, 1)
tlab_1 = sp_0x18
tlab_1.length = ret_7<<ret_7>>32
sp_0x10 = " "
sp_0x8 = tlab_1
ret_22 = ?java.lang.StringConcatHelper.prepend(tlab_1, " ", ret_7)
ret_23 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_22)
rsi = ret_23
java.io.PrintStream.write(sp_0x20, ret_23)
rdi = 1
rdx = 1
rcx = 3
while(true)
{
if(sp_0x44<=rcx)
{
break
}
else
{
sp_0x34 = rcx
rdi = rdi+rdx
r9 = rdi
sp_0x30 = rdx
sp_0x2c = r9
ret_11 = java.lang.StringConcatHelper.mix(1, r9)
tlab_2 = sp_0x18
tlab_2.length = ret_11<<ret_11>>32
sp_0x8 = tlab_2
ret_17 = ?java.lang.StringConcatHelper.prepend(tlab_2, sp_0x10, ret_11)
ret_18 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_17)
rsi = ret_18
java.io.PrintStream.write(sp_0x20, ret_18)
rcx = sp_0x34+1
rdi = sp_0x30
rdx = sp_0x2c
}
}
}
java.io.PrintStream.newLine(sp_0x20, rsi)
return
sp_0x44はプログラムに入力するパラメータで、countです。Javaコードのforループはcount >= 3の場合にのみ実行されます。ここでforループはwhileループに変換されていますが、本質的に同じセマンティクスです。whileループの外側では、count=3の場合のロジックが実行されます。count <= 3の場合、プログラムは実行を完了し、再びwhileループに入ることはありません。これはGraalVMがコンパイル時に行った最適化の可能性もあります。
ループの終了条件を見てみましょう。
if(sp_0x44<=rcx)
{
break
}
これは以下に対応します
i < count
同時にrcxも各イテーション中に蓄積されています。
sp_0x34 = rcx
rcx = sp_0x34+1
これは以下に対応します
++i
次に、ループ内の数値加算のロジックが復元コードでどのように反映されているか見てみましょう。元のコードは以下の通りです:
for(......){
......
n3 = n1 + n2;
n1 = n2;
n2 = n3;
......
}
復元後のコードは
while(true){
......
rdi = rdi+rdx -> n3 = n1 + n2
r9 = rdi -> r9 = n3
sp_0x30 = rdx -> sp_0x30 = n2
sp_0x2c = r9 -> sp_0x2c = n3
rdi = sp_0x30 -> n1 = sp_0x30 = n2
rdx = sp_0x2c -> n2 = sp_0x2c = n3
......
}
ループ内のその他のコードは以前と同様に文字列連結と出力操作を実行します。復元されたコードは基本的に元のコードの実行ロジックを反映しています。
さらなる改善が必要
現在、このツールはプログラムの制御フローを部分的に復元し、ある程度のデータフロー分析と関数名の復元を達成しています。完全で使用可能なツールになるためには、まだ以下を達成する必要があります:
より正確な関数名、関数パラメータ、関数戻り値の復元
正確なオブジェクト情報とフィールドの復元
より正確な式とオブジェクト型の推論
ステートメントの統合と簡略化
バイナリ保護に関する考察
このプロジェクトの目的は、NativeImageのリバースエンジニアリングの実現可能性を探ることです。現在の成果に基づくと、NativeImageのリバースエンジニアリングは実現可能であり、コード保護に対してより高い課題をもたらします。多くの開発者はソフトウェアをバイナリにコンパイルすればセキュリティを保証できると信じており、バイナリコードの保護を怠っています。C/C++で書かれたソフトウェアの場合、IDAなどの多くのツールが既に優れたリバースエンジニアリング効果を持っており、Javaプログラムよりも多くの情報を露出させることもあります。バイナリ形式で配布しているにもかかわらず、関数名のシンボル情報を削除していないソフトウェアさえ見たことがあります。これは裸で走っているのと同じです。
すべてのコードはロジックで構成されています。ロジックが含まれている限り、リバース手段を通じてそのロジックを復元することが可能です。唯一の違いは復元の難易度です。コード保護はそのような復元の難易度を最大化することです。