NativeImage 역공학
Java 코드의 복원과 보호는 오래되고 자주 논의되는 주제입니다. Java 클래스 파일을 저장하는 데 사용되는 바이트코드 형식에는 많은 메타 정보가 포함되어 있어, 원래 코드로 쉽게 복원할 수 있습니다. Java 코드를 보호하기 위해 업계에서는 난독화, 바이트코드 암호화, JNI 보호 등 많은 방법을 채택했습니다. 그러나 어떤 방법을 사용하든 크래킹할 수 있는 방법과 수단이 여전히 있습니다.
바이너리 컴파일은 항상 비교적 효과적인 코드 보호 방법으로 여겨져 왔습니다. Java의 바이너리 컴파일은 AOT(Ahead of Time) 기술, 즉 사전 컴파일로 지원됩니다.
그러나 Java 언어의 동적 특성으로 인해 바이너리 컴파일은 리플렉션, 동적 프록시, JNI 로딩 등의 문제를 처리해야 하며, 이는 많은 어려움을 초래합니다. 따라서 오랫동안 Java에서 프로덕션 환경에 광범위하게 적용할 수 있는 성숙하고 신뢰할 수 있으며 적응력 있는 AOT 컴파일 도구가 부족했습니다. (Excelsior JET이라는 도구가 있었지만, 지금은 중단된 것 같습니다.)
2019년 5월, Oracle은 다중 언어를 지원하는 가상 머신인 GraalVM 19.0을 출시했으며, 이것이 첫 번째 프로덕션 준비 버전이었습니다. GraalVM은 Java 프로그램의 AOT 컴파일을 달성할 수 있는 NativeImage 도구를 제공합니다. 여러 해의 개발을 거쳐 NativeImage는 이제 매우 성숙해졌으며, SpringBoot 3.0에서 전체 SpringBoot 프로젝트를 실행 파일로 컴파일할 수 있습니다. 컴파일된 파일은 빠른 시작 속도, 낮은 메모리 사용량, 뛰어난 성능을 가지고 있습니다.
그렇다면, 바이너리 컴파일 시대에 진입한 Java 프로그램의 코드는 바이트코드 시대처럼 쉽게 역공학할 수 있을까요? NativeImage로 컴파일된 바이너리 파일의 특성은 무엇이며, 바이너리 컴파일의 강도가 중요한 코드를 보호하기에 충분할까요?
이러한 문제를 탐구하기 위해, 최근 NativeImage 분석 도구를 개발하여 어느 정도의 역공학 효과를 달성했습니다.
프로젝트
https://github.com/vlinx-io/NativeImageAnalyzer
NativeImage 생성
먼저, NativeImage를 생성해야 합니다. NativeImage는 GraalVM에서 제공됩니다. GraalVM을 다운로드하려면 https://www.graalvm.org/ 에서 Java 17 버전을 다운로드하세요. 다운로드 후 환경 변수를 설정합니다. GraalVM에는 JDK가 포함되어 있으므로, 직접 java 명령을 실행하는 데 사용할 수 있습니다.
$GRAALVM_HOME/bin을 환경 변수에 추가한 다음, native-image 도구를 설치하기 위해 다음 명령을 실행합니다.
gu install native-image
간단한 Java 프로그램
간단한 Java 프로그램을 작성합니다. 예를 들어:
public class Hello {
public static void main(String[] args){
System.out.println("Hello World!");
}
}
위의 Java 프로그램을 컴파일하고 실행합니다:
javac Hello.java
java -cp . Hello
다음과 같은 출력을 얻을 수 있습니다:
Hello World!
컴파일 환경 준비
Windows 사용자의 경우 먼저 Visual Studio를 설치해야 합니다. Linux 또는 macOS 사용자의 경우 gcc와 clang과 같은 도구를 미리 설치해야 합니다.
Windows 사용자는 native-image 명령을 실행하기 전에 Visual Studio의 환경 변수를 설정해야 합니다. 다음 명령으로 설정할 수 있습니다:
"C:\Program Files (x86)\Microsoft Visual Studio\2017\Community\VC\Auxiliary\Build\vcvars64.bat"
Visual Studio의 설치 경로와 버전이 다른 경우, 관련 경로 정보를 적절히 조정하세요.
native-image로 컴파일
이제 native-image 명령을 사용하여 위의 Java 프로그램을 바이너리 파일로 컴파일합니다. native-image 명령의 형식은 java 명령 형식과 동일하며, -cp, -jar 등의 매개변수도 있습니다. java 명령으로 프로그램을 실행하는 것과 동일한 방법으로 바이너리 컴파일을 수행하며, 명령을 java에서 native-image로 바꾸기만 하면 됩니다. 다음 명령을 실행합니다:
native-image -cp . Hello
일정 시간의 컴파일 후(더 많은 CPU와 메모리를 소모할 수 있음), 컴파일된 바이너리 파일을 얻을 수 있습니다. 출력 파일 이름은 기본적으로 메인 클래스 이름의 소문자로, 이 경우 "hello"입니다. Windows에서는 "hello.exe"가 됩니다. "file" 명령을 사용하여 이 파일의 유형을 확인하면, 실제로 바이너리 파일임을 알 수 있습니다.
file hello
hello: Mach-O 64-bit executable x86_64
이 파일을 실행하면, 이전에 java -cp . Hello를 사용하여 얻은 결과와 동일한 출력이 나옵니다.
Hello World!
NativeImage 분석
IDA를 사용한 분석
IDA를 사용하여 위에서 컴파일된 hello를 열고, Exports를 클릭하여 심볼 테이블을 보면, svm_code_section 심볼을 볼 수 있으며, 그 주소가 Java Main 함수의 진입 주소입니다.
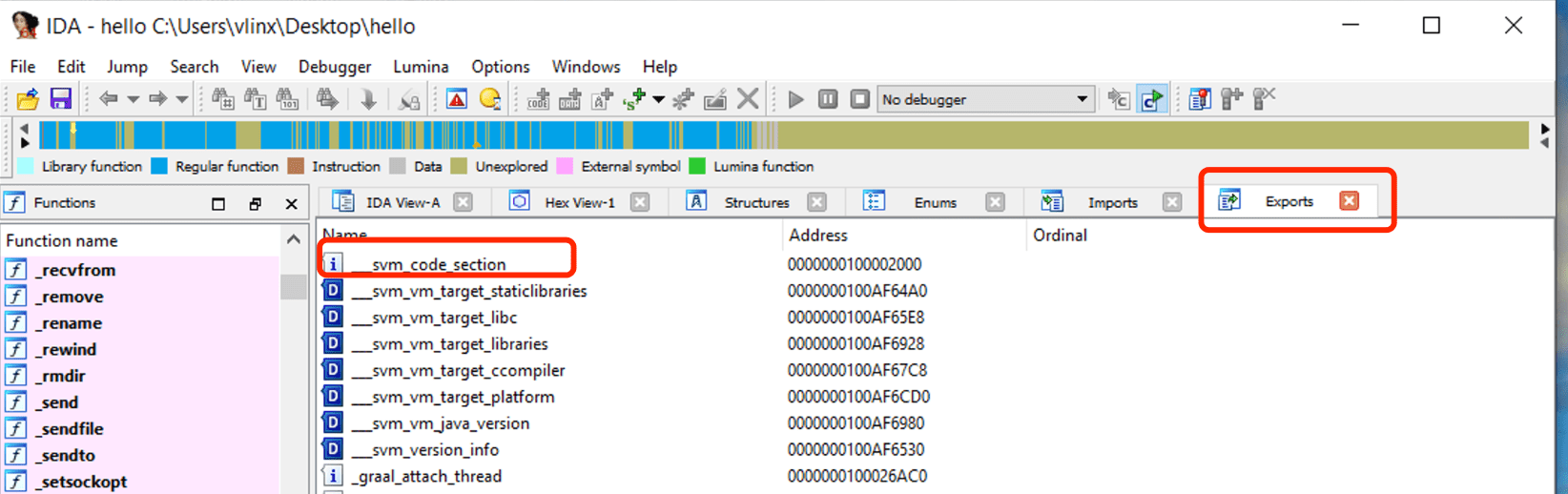
이 주소로 이동하여 어셈블리 코드를 봅니다.
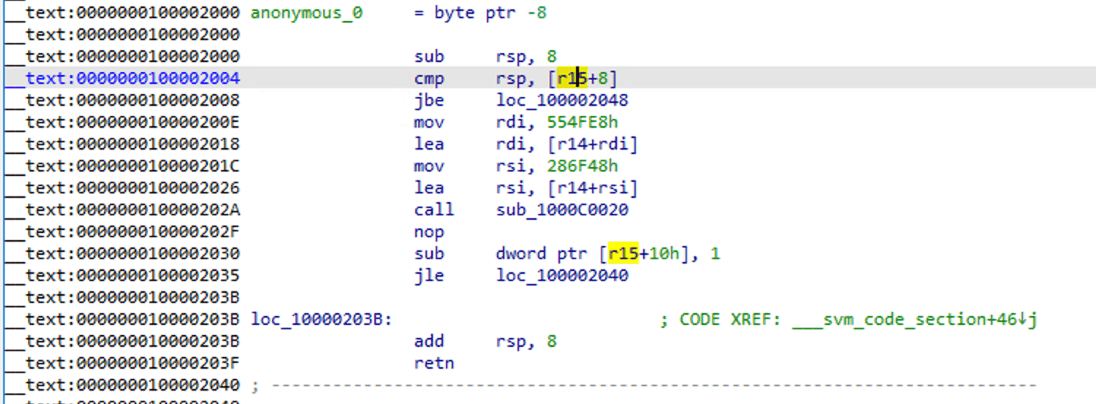
표준 어셈블리 함수가 되었음을 볼 수 있습니다. F5를 사용하여 디컴파일합니다.
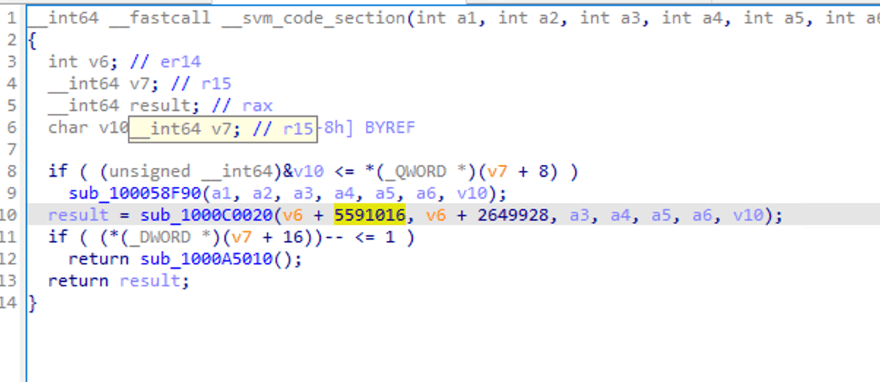
일부 함수 호출과 매개변수 전달을 볼 수 있지만, 로직을 쉽게 파악하기는 어렵습니다.
sub_1000C0020을 더블 클릭하여 함수 호출 내부를 살펴보면, IDA가 분석 실패를 알려줍니다.
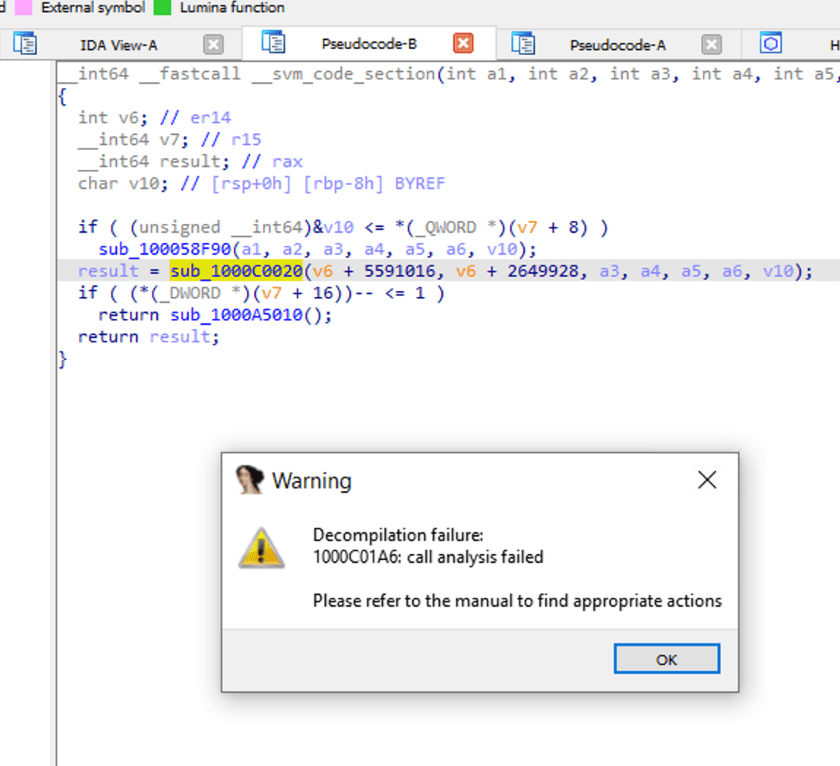
NativeImage의 디컴파일 로직
NativeImage의 컴파일은 JVM 컴파일을 기반으로 하므로, 바이너리 코드를 VM 보호 계층으로 감싸는 것으로 이해할 수도 있습니다. 따라서 IDA와 같은 도구는 해당 정보와 대상 처리 조치 없이는 이를 잘 역공학할 수 없습니다.
그러나 형식에 관계없이, 바이트코드든 바이너리 형태든, 클래스 정보, 필드 정보, 함수 호출, 매개변수 전달과 같은 JVM 실행의 기본 요소는 반드시 존재합니다. 이러한 사고방식을 바탕으로, 제가 개발한 분석 도구는 어느 정도의 복원 효과를 달성할 수 있으며, 추가 개선을 통해 높은 수준의 복원 정확도를 달성할 수 있습니다.
NativeImageAnalyzer를 사용한 분석
https://github.com/vlinx-io/NativeImageAnalyzer 에서 NativeImageAnalyzer를 다운로드하세요.
다음 명령을 실행하여 역분석을 수행합니다. 현재는 메인 클래스의 Main 함수만 분석합니다.
native-image-analyzer hello
출력은 다음과 같습니다.
java.io.PrintStream.writeln(java.io.PrintStream@0x554fe8, "Hello World!", rcx)
return
원래 코드를 다시 살펴보겠습니다.
public static void main(String[] args){
System.out.println("Hello World!");
}
이제 System.out의 정의를 살펴보겠습니다.
public static final PrintStream out = null;
System 클래스의 'out' 변수가 PrintStream 타입의 변수이며 정적 변수임을 알 수 있습니다. 컴파일 중에 NativeImage는 이 클래스의 인스턴스를 Heap이라는 영역에 직접 컴파일하고, 바이너리 코드는 호출을 위해 Heap 영역에서 직접 이 인스턴스를 가져옵니다. 복원된 코드를 살펴보겠습니다.
java.io.PrintStream.writeln(java.io.PrintStream@0x554fe8, "Hello World!", rcx)
return
이 java.io.PrintStream@0x554fe8은 Heap 영역에서 읽은 java.io.PrintStream 인스턴스 변수이며, 메모리 주소 0x554fe8에 위치합니다.
java.io.PrintStream.writeln 함수의 정의를 살펴보겠습니다.
private void writeln(String s) {
......
}
여기서 writeln 함수에 String 인수가 있지만, 복원된 코드에서 왜 세 개의 인수가 전달되는지 볼 수 있습니다. 먼저 writeln은 this 하나만 숨기는 클래스 멤버 메서드이며, 변수는 호출자를 가리키므로 첫 번째 매개변수인 java.io.PrintStream@0x554fe8이 전달됩니다. 세 번째 매개변수 rcx의 경우, 어셈블리 코드를 분석하는 과정에서 이 함수가 세 개의 매개변수로 호출되었다고 판단했기 때문입니다. 그러나 정의를 살펴보면 이 함수는 실제로 두 개의 매개변수만 호출합니다. 이것은 향후 이 도구에서 개선이 필요한 부분이기도 합니다.
더 복잡한 프로그램
이제 피보나치 수열을 계산하는 등 더 복잡한 프로그램을 분석해 보겠습니다. 코드는 다음과 같습니다.
class Fibonacci {
public static void main(String[] args) {
int count = Integer.parseInt(args[0]);
int n1 = 0, n2 = 1, n3;
System.out.print(n1 + " " + n2);
for (int i = 2; i < count; ++i){
n3 = n1 + n2;
System.out.print(" " + n3);
n1 = n2;
n2 = n3;
}
System.out.println();
}
}
컴파일하고 실행합니다.
javac Fibonacci.java
native-image -cp . Fibonacci
./fibonacci 10
0 1 1 2 3 5 8 13 21 34
NativeImageAnalyzer를 사용하여 복원한 코드는 다음과 같습니다.
rdi = rdi[0]
ret_0 = java.lang.Integer.parseInt(rdi, 10)
sp_0x44 = ret_0
ret_1 = java.lang.StringConcatHelper.mix(1, 1)
ret_2 = java.lang.StringConcatHelper.mix(ret_1, 0)
sp_0x20 = java.io.PrintStream@0x554fe8
sp_0x18 = Class{[B}_1
tlab_0 = Class{[B}_1
tlab_0.length = ret_2<<ret_2>>32
sp_0x10 = tlab_0
ret_28 = ?java.lang.StringConcatHelper.prepend(tlab_0, " ", ret_2)
ret_29 = java.lang.StringConcatHelper.prepend(ret_28, sp_0x10, 0)
ret_30 = ?java.lang.StringConcatHelper.newString(sp_0x10, ret_29)
java.io.PrintStream.write(sp_0x20, ret_30)
if(sp_0x44>=3)
{
ret_7 = java.lang.StringConcatHelper.mix(1, 1)
tlab_1 = sp_0x18
tlab_1.length = ret_7<<ret_7>>32
sp_0x10 = " "
sp_0x8 = tlab_1
ret_22 = ?java.lang.StringConcatHelper.prepend(tlab_1, " ", ret_7)
ret_23 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_22)
rsi = ret_23
java.io.PrintStream.write(sp_0x20, ret_23)
rdi = 1
rdx = 1
rcx = 3
while(true)
{
if(sp_0x44<=rcx)
{
break
}
else
{
sp_0x34 = rcx
rdi = rdi+rdx
r9 = rdi
sp_0x30 = rdx
sp_0x2c = r9
ret_11 = java.lang.StringConcatHelper.mix(1, r9)
tlab_2 = sp_0x18
tlab_2.length = ret_11<<ret_11>>32
sp_0x8 = tlab_2
ret_17 = ?java.lang.StringConcatHelper.prepend(tlab_2, sp_0x10, ret_11)
ret_18 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_17)
rsi = ret_18
java.io.PrintStream.write(sp_0x20, ret_18)
rcx = sp_0x34+1
rdi = sp_0x30
rdx = sp_0x2c
}
}
}
java.io.PrintStream.newLine(sp_0x20, rsi)
return
복원된 코드와 원래 코드를 비교해 보겠습니다.
rdi = rdi[0]
ret_0 = java.lang.Integer.parseInt(rdi, 10)
sp_0x44 = ret_0
이것은 다음에 해당합니다.
int count = Integer.parseInt(args[0]);
rdi는 함수의 첫 번째 인수를 전달하는 데 사용되는 레지스터입니다. Windows의 경우 rdi = rdi[0]은 args[0]에 해당합니다. 그 후 java.lang.Integer.parseInt를 호출하여 int 값을 파싱하고, 반환값을 스택 변수 sp_0x44에 할당합니다.
int n1 = 0, n2 = 1, n3;
System.out.print(n1 + " " + n2);
이것은 다음에 해당합니다.
ret_1 = java.lang.StringConcatHelper.mix(1, 1)
ret_2 = java.lang.StringConcatHelper.mix(ret_1, 0)
sp_0x20 = java.io.PrintStream@0x554fe8
sp_0x18 = Class{[B}_1
tlab_0 = Class{[B}_1
tlab_0.length = ret_2<<ret_2>>32
sp_0x10 = tlab_0
ret_28 = ?java.lang.StringConcatHelper.prepend(tlab_0, " ", ret_2)
ret_29 = java.lang.StringConcatHelper.prepend(ret_28, sp_0x10, 0)
ret_30 = ?java.lang.StringConcatHelper.newString(sp_0x10, ret_29)
java.io.PrintStream.write(sp_0x20, ret_30)
Java 코드에서 간단한 문자열 연결 작업은 실제로 세 가지 함수 호출로 변환됩니다: StringConcatHelper.mix, StringConcatHelper.prepend, StringConcatHelper.newString. 이 중 StringConcatHelper.mix는 연결된 문자열의 길이를 계산하고, StringConcatHelper.prepend는 구체적인 문자열 내용을 담고 있는 byte[] 배열을 결합하며, StringConcatHelper.newString은 byte[] 배열에서 새 String 객체를 생성합니다.
위의 코드에서 두 가지 유형의 변수 이름을 볼 수 있습니다: sp_0x18과 tlab_0. sp_로 시작하는 변수는 스택에 할당된 변수를 나타내고, tlab_으로 시작하는 변수는 Thread Local Allocation Buffers에 할당된 변수를 나타냅니다. 이것은 이 두 가지 유형의 변수 이름의 유래를 설명할 뿐입니다. 복원된 코드에서는 이 두 가지 유형의 변수 사이에 구분이 없습니다. Thread Local Allocation Buffers에 관한 정보는 직접 검색해 주세요.
여기서 tlab_0에 Class{[B}_1을 할당합니다. Class{[B}_1의 의미는 byte[] 타입의 인스턴스입니다. [B는 byte[]의 Java 디스크립터를 나타내며, _1은 이 타입의 첫 번째 변수임을 나타냅니다. 해당 타입에 대해 후속 변수가 정의되면 인덱스가 그에 따라 증가합니다. 예를 들어 Class{[B]}_2, Class{[B]}_3 등입니다. 동일한 표현이 다른 타입에도 적용됩니다. 예를 들어 Class{java.lang.String}_1, Class{java.util.HashMap}_2 등입니다.
위 코드의 로직은 간단히 byte[] 배열 인스턴스를 생성하고 tlab0에 할당하는 것입니다. 배열의 길이는 ret_2 << ret_2 >> 32입니다. 배열의 길이가 ret_2 << ret_2 >> 32인 이유는 String의 길이를 계산할 때 인코딩에 따라 배열의 길이를 변환해야 하기 때문입니다. java.lang.String.java의 관련 코드를 참조할 수 있습니다. 다음으로 prepend 함수가 0, 1, 공백을 tlab0에 결합한 다음 tlab_0에서 새 String 객체 ret_30을 생성하고 java.io.PrintStream.write 함수에 전달하여 인쇄 출력합니다. 실제로 여기서 prepend 함수에 의해 복원된 매개변수는 매우 정확하지 않으며 위치도 올바르지 않습니다. 이것은 향후 추가 개선이 필요한 부분입니다.
두 줄의 Java 코드를 실제 실행 로직으로 변환한 후에도 상당히 복잡합니다. 향후에는 현재 복원된 코드를 기반으로 분석하고 통합하여 단순화할 수 있습니다.
계속 진행하겠습니다.
for (int i = 2; i < count; ++i){
n3 = n1 + n2;
System.out.print(" " + n3);
n1 = n2;
n2 = n3;
}
System.out.println();
이것은 다음에 해당합니다.
if(sp_0x44>=3)
{
ret_7 = java.lang.StringConcatHelper.mix(1, 1)
tlab_1 = sp_0x18
tlab_1.length = ret_7<<ret_7>>32
sp_0x10 = " "
sp_0x8 = tlab_1
ret_22 = ?java.lang.StringConcatHelper.prepend(tlab_1, " ", ret_7)
ret_23 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_22)
rsi = ret_23
java.io.PrintStream.write(sp_0x20, ret_23)
rdi = 1
rdx = 1
rcx = 3
while(true)
{
if(sp_0x44<=rcx)
{
break
}
else
{
sp_0x34 = rcx
rdi = rdi+rdx
r9 = rdi
sp_0x30 = rdx
sp_0x2c = r9
ret_11 = java.lang.StringConcatHelper.mix(1, r9)
tlab_2 = sp_0x18
tlab_2.length = ret_11<<ret_11>>32
sp_0x8 = tlab_2
ret_17 = ?java.lang.StringConcatHelper.prepend(tlab_2, sp_0x10, ret_11)
ret_18 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_17)
rsi = ret_18
java.io.PrintStream.write(sp_0x20, ret_18)
rcx = sp_0x34+1
rdi = sp_0x30
rdx = sp_0x2c
}
}
}
java.io.PrintStream.newLine(sp_0x20, rsi)
return
sp_0x44는 프로그램에 입력하는 매개변수, 즉 count입니다. Java 코드의 for 루프는 count >= 3인 경우에만 실행됩니다. 여기서 for 루프는 while 루프로 다시 변환되었지만, 본질적으로 동일한 의미를 가집니다. while 루프 외부에서 프로그램은 count=3인 로직을 실행합니다. count <= 3이면 프로그램은 실행을 완료하고 while 루프에 다시 들어가지 않습니다. 이것은 GraalVM이 컴파일 중에 수행한 최적화일 수도 있습니다.
루프의 종료 조건을 다시 살펴보겠습니다.
if(sp_0x44<=rcx)
{
break
}
이것은 다음에 해당합니다.
i < count
동시에 rcx는 각 반복 과정에서 누적되고 있습니다.
sp_0x34 = rcx
rcx = sp_0x34+1
이것은 다음에 해당합니다.
++i
다음으로, 루프 본문에서 숫자를 더하는 로직이 복원된 코드에서 어떻게 반영되는지 살펴보겠습니다. 원래 코드는 다음과 같습니다:
for(......){
......
n3 = n1 + n2;
n1 = n2;
n2 = n3;
......
}
복원 후의 코드는 다음과 같습니다.
while(true){
......
rdi = rdi+rdx -> n3 = n1 + n2
r9 = rdi -> r9 = n3
sp_0x30 = rdx -> sp_0x30 = n2
sp_0x2c = r9 -> sp_0x2c = n3
rdi = sp_0x30 -> n1 = sp_0x30 = n2
rdx = sp_0x2c -> n2 = sp_0x2c = n3
......
}
루프 본문의 나머지 코드는 이전과 마찬가지로 문자열 연결 및 출력 작업을 수행합니다. 복원된 코드는 기본적으로 원래 코드의 실행 로직을 반영합니다.
추가 개선이 필요합니다
현재 이 도구는 프로그램 제어 흐름을 부분적으로 복원하고, 어느 정도의 데이터 흐름 분석과 함수 이름 복원을 달성했습니다. 완전하고 사용 가능한 도구가 되려면 다음을 달성해야 합니다:
더 정확한 함수 이름, 함수 매개변수, 함수 반환값 복원
정확한 객체 정보와 필드 복원
더 정확한 표현식과 객체 타입 추론
문장 통합 및 단순화
바이너리 보호에 대한 고찰
이 프로젝트의 목적은 NativeImage 역공학의 실현 가능성을 탐구하는 것입니다. 현재 성과를 기반으로 NativeImage 역공학은 실현 가능하며, 이는 코드 보호에 더 높은 도전을 가져옵니다. 많은 개발자들이 소프트웨어를 바이너리로 컴파일하면 보안을 보장할 수 있다고 믿으며, 바이너리 코드의 보호를 소홀히 합니다. C/C++로 작성된 소프트웨어의 경우, IDA와 같은 많은 도구가 이미 훌륭한 역공학 효과를 가지고 있으며, 때때로 Java 프로그램보다 더 많은 정보를 노출하기도 합니다. 심지어 함수 이름의 심볼 정보를 제거하지 않고 바이너리 형태로 배포하는 소프트웨어도 본 적이 있는데, 이는 아무런 보호 없이 실행하는 것과 마찬가지입니다.
모든 코드는 로직으로 구성됩니다. 로직이 포함되어 있는 한, 역공학을 통해 그 로직을 복원하는 것이 가능합니다. 유일한 차이점은 복원의 난이도에 있습니다. 코드 보호는 이러한 복원의 난이도를 최대화하는 것입니다.