Engenharia Reversa de NativeImage
Restaurar e proteger código Java é uma questão antiga e frequentemente discutida. Devido ao formato de bytecode usado para armazenar arquivos class Java, que contém muita meta-informação, pode ser facilmente restaurado ao seu código original. Para proteger o código Java, a indústria adotou muitos métodos, como ofuscação, criptografia de bytecode, proteção JNI, e assim por diante. No entanto, independentemente do método usado, ainda existem formas e meios de quebrá-lo.
A compilação binária sempre foi considerada um método relativamente eficaz de proteção de código. A compilação binária do Java é suportada como tecnologia AOT (Ahead of Time), que significa pré-compilação.
No entanto, devido à natureza dinâmica da linguagem Java, a compilação binária precisa lidar com questões como reflexão, proxy dinâmico, carregamento JNI, etc., o que apresenta muitas dificuldades. Portanto, por muito tempo, houve falta de uma ferramenta madura, confiável e adaptável para compilação AOT em Java que pudesse ser amplamente aplicada em ambientes de produção. (Costumava existir uma ferramenta chamada Excelsior JET, mas parece ter sido descontinuada agora.)
Em maio de 2019, a Oracle lançou o GraalVM 19.0, uma máquina virtual com suporte a múltiplas linguagens, que foi sua primeira versão pronta para produção. O GraalVM fornece a ferramenta NativeImage que pode alcançar compilação AOT de programas Java. Após vários anos de desenvolvimento, o NativeImage está agora muito maduro, e o SpringBoot 3.0 pode usá-lo para compilar todo o projeto SpringBoot em um arquivo executável. O arquivo compilado tem velocidade de inicialização rápida, baixo uso de memória e excelente desempenho.
Então, para programas Java que entraram na era da compilação binária, seu código ainda é tão facilmente reversível como era na era do bytecode? Quais são as características dos arquivos binários compilados pelo NativeImage, e a intensidade da compilação binária é suficiente para proteger código importante?
Para explorar essas questões, desenvolvemos recentemente uma ferramenta de análise de NativeImage, que alcançou um certo grau de efeito reverso.
Projeto
https://github.com/vlinx-io/NativeImageAnalyzer
Gerando NativeImage
Primeiro, precisamos gerar um NativeImage. O NativeImage vem do GraalVM. Para baixar o GraalVM, vá para https://www.graalvm.org/ e baixe a versão para Java 17. Após o download, configure a variável de ambiente. Como o GraalVM contém um JDK, você pode usá-lo diretamente para executar o comando java.
Adicione $GRAALVM_HOME/bin à variável de ambiente, e depois execute o seguinte comando para instalar a ferramenta native-image
gu install native-image
Um programa Java simples
Escreva um programa Java simples, por exemplo:
public class Hello {
public static void main(String[] args){
System.out.println("Hello World!");
}
}
Compile e execute o programa Java acima:
javac Hello.java
java -cp . Hello
Você obterá a seguinte saída:
Hello World!
Preparação do Ambiente de Compilação
Se você for um usuário Windows, precisará instalar o Visual Studio primeiro. Se for um usuário Linux ou macOS, precisará instalar ferramentas como gcc e clang previamente.
Para usuários Windows, é preciso configurar a variável de ambiente para o Visual Studio antes de executar o comando native-image. Você pode configurá-la usando o seguinte comando:
"C:\Program Files (x86)\Microsoft Visual Studio\2017\Community\VC\Auxiliary\Build\vcvars64.bat"
Se o caminho de instalação e a versão do Visual Studio forem diferentes, ajuste as informações de caminho relacionadas conforme necessário.
Compilar com native-image
Agora use o comando native-image para compilar o programa Java acima em um arquivo binário. O formato do comando native-image é o mesmo que o formato do comando java, e também possui os parâmetros -cp e -jar. Como usar o comando java para executar o programa, use o mesmo método para compilação binária, apenas substitua o comando de java por native-image. Execute o seguinte comando
native-image -cp . Hello
Após um período de compilação, pode consumir mais CPU e memória. Você pode obter um arquivo binário compilado, e o nome do arquivo de saída é por padrão o nome da classe principal em minúsculas, que neste caso é "hello". Se estiver no Windows, será "hello.exe". Use o comando "file" para verificar o tipo deste arquivo, você pode ver que é de fato um arquivo binário.
file hello
hello: Mach-O 64-bit executable x86_64
Execute este arquivo, e sua saída será a mesma obtida anteriormente usando java -cp . Hello
Hello World!
Analisando NativeImage
Analisando com IDA
Use o IDA para abrir o hello compilado dos passos acima, clique em Exports para visualizar a tabela de símbolos, você pode ver o símbolo svm_code_section, e seu endereço é o endereço de entrada da função Main do Java.
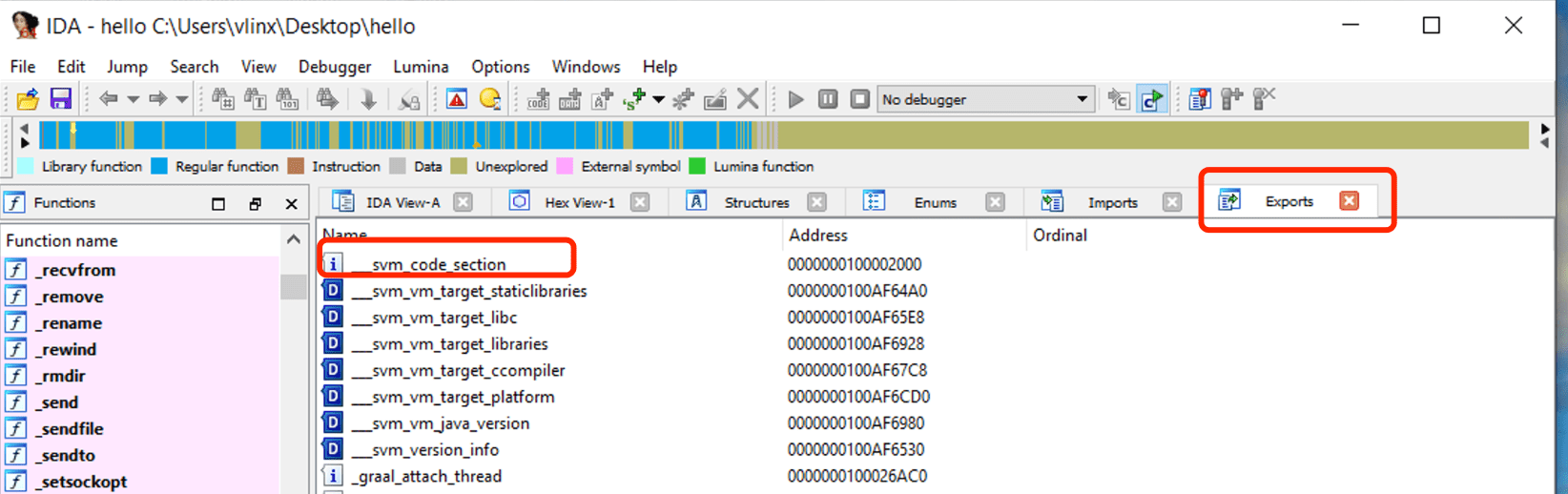
Navegue até este endereço para visualizar o código assembly
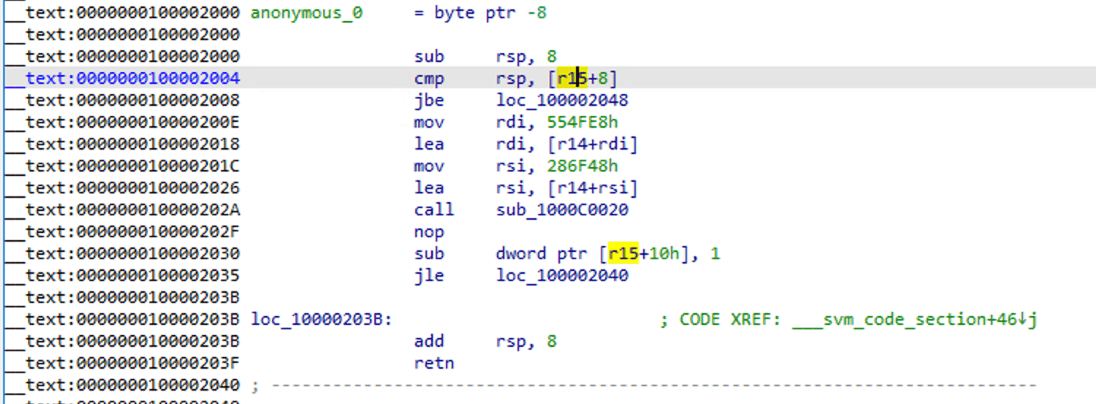
Você pode ver que se tornou uma função assembly padrão, use F5 para descompilar
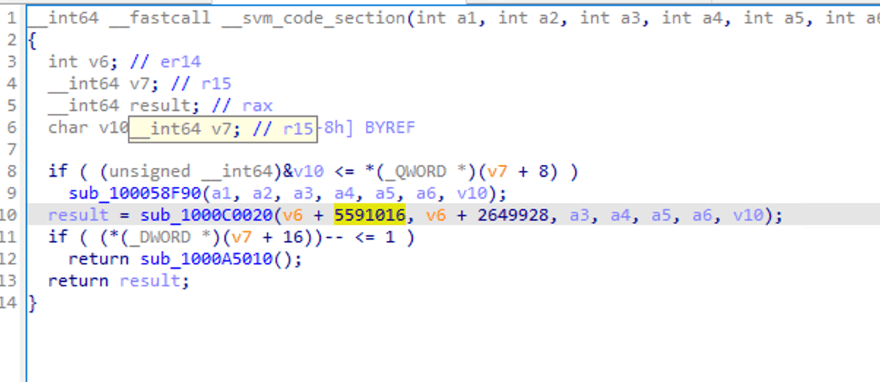
Algumas chamadas de função podem ser vistas, e alguns parâmetros são passados, mas não é fácil ver a lógica.
Quando clicamos duas vezes em sub_1000C0020, vamos olhar dentro da chamada de função. O IDA indica falha na análise.
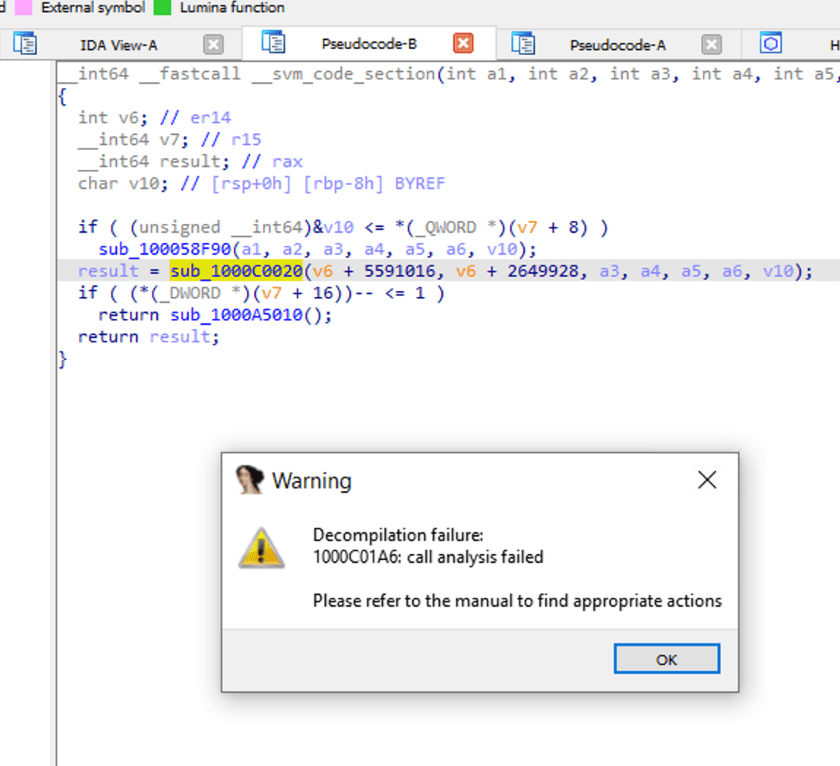
Lógica de Descompilação do NativeImage
Como a compilação do NativeImage é baseada na compilação JVM, também pode ser entendida como envolver código binário com uma camada de proteção VM. Portanto, ferramentas como o IDA são incapazes de fazer engenharia reversa adequada na ausência de informações correspondentes e medidas de processamento direcionadas.
No entanto, independentemente do formato, seja bytecode ou forma binária, alguns elementos básicos da execução JVM estão fadados a existir, como informações de classe, informações de campo, invocação de funções e passagem de parâmetros. Com base nesse raciocínio, a ferramenta de análise que desenvolvi pode alcançar um certo nível de efeito de restauração e, com melhorias adicionais, ter a capacidade de alcançar um alto nível de precisão de restauração.
Analisando com NativeImageAnalyzer
Visite https://github.com/vlinx-io/NativeImageAnalyzer para baixar o NativeImageAnalyzer
Execute o seguinte comando para análise reversa, atualmente analisando apenas a função Main da classe principal
native-image-analyzer hello
A saída é a seguinte
java.io.PrintStream.writeln(java.io.PrintStream@0x554fe8, "Hello World!", rcx)
return
Vamos olhar novamente o código original.
public static void main(String[] args){
System.out.println("Hello World!");
}
Agora vamos olhar a definição de System.out.
public static final PrintStream out = null;
Você pode ver que a variável 'out' da classe System é uma variável do tipo PrintStream, e é uma variável estática. Durante a compilação, o NativeImage compila diretamente uma instância desta classe em uma região chamada Heap, e o código binário recupera diretamente esta instância da região Heap para invocação. Vamos olhar o código original após a restauração.
java.io.PrintStream.writeln(java.io.PrintStream@0x554fe8, "Hello World!", rcx)
return
Este java.io.PrintStream@0x554fe8 é apenas a variável de instância java.io.PrintStream lida da área Heap e localizada no endereço de memória 0x554fe8.
Vamos olhar a definição da função java.io.PrintStream.writeln
private void writeln(String s) {
......
}
Aqui podemos ver que há um argumento String na função writeln, mas no código restaurado, por que três argumentos são passados? Primeiro, writeln é um método membro de classe que oculta apenas um this, a variável aponta para o chamador, que é o primeiro parâmetro passado, java.io.PrintStream@0x554fe8. Quanto ao terceiro parâmetro rcx, é porque durante o processo de análise do código assembly, foi determinado que esta função foi chamada com três parâmetros. No entanto, ao examinar a definição, sabemos que esta função na verdade chama apenas dois parâmetros. Esta é também uma área que precisa de melhoria para esta ferramenta no futuro.
Um programa mais complexo
Agora vamos analisar um programa mais complexo, como calcular uma sequência de Fibonacci, com o seguinte código
class Fibonacci {
public static void main(String[] args) {
int count = Integer.parseInt(args[0]);
int n1 = 0, n2 = 1, n3;
System.out.print(n1 + " " + n2);
for (int i = 2; i < count; ++i){
n3 = n1 + n2;
System.out.print(" " + n3);
n1 = n2;
n2 = n3;
}
System.out.println();
}
}
Compile e execute
javac Fibonacci.java
native-image -cp . Fibonacci
./fibonacci 10
0 1 1 2 3 5 8 13 21 34
O código obtido após a restauração usando NativeImageAnalyzer é o seguinte
rdi = rdi[0]
ret_0 = java.lang.Integer.parseInt(rdi, 10)
sp_0x44 = ret_0
ret_1 = java.lang.StringConcatHelper.mix(1, 1)
ret_2 = java.lang.StringConcatHelper.mix(ret_1, 0)
sp_0x20 = java.io.PrintStream@0x554fe8
sp_0x18 = Class{[B}_1
tlab_0 = Class{[B}_1
tlab_0.length = ret_2<<ret_2>>32
sp_0x10 = tlab_0
ret_28 = ?java.lang.StringConcatHelper.prepend(tlab_0, " ", ret_2)
ret_29 = java.lang.StringConcatHelper.prepend(ret_28, sp_0x10, 0)
ret_30 = ?java.lang.StringConcatHelper.newString(sp_0x10, ret_29)
java.io.PrintStream.write(sp_0x20, ret_30)
if(sp_0x44>=3)
{
ret_7 = java.lang.StringConcatHelper.mix(1, 1)
tlab_1 = sp_0x18
tlab_1.length = ret_7<<ret_7>>32
sp_0x10 = " "
sp_0x8 = tlab_1
ret_22 = ?java.lang.StringConcatHelper.prepend(tlab_1, " ", ret_7)
ret_23 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_22)
rsi = ret_23
java.io.PrintStream.write(sp_0x20, ret_23)
rdi = 1
rdx = 1
rcx = 3
while(true)
{
if(sp_0x44<=rcx)
{
break
}
else
{
sp_0x34 = rcx
rdi = rdi+rdx
r9 = rdi
sp_0x30 = rdx
sp_0x2c = r9
ret_11 = java.lang.StringConcatHelper.mix(1, r9)
tlab_2 = sp_0x18
tlab_2.length = ret_11<<ret_11>>32
sp_0x8 = tlab_2
ret_17 = ?java.lang.StringConcatHelper.prepend(tlab_2, sp_0x10, ret_11)
ret_18 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_17)
rsi = ret_18
java.io.PrintStream.write(sp_0x20, ret_18)
rcx = sp_0x34+1
rdi = sp_0x30
rdx = sp_0x2c
}
}
}
java.io.PrintStream.newLine(sp_0x20, rsi)
return
Compare o código restaurado com o código original.
rdi = rdi[0]
ret_0 = java.lang.Integer.parseInt(rdi, 10)
sp_0x44 = ret_0
O correspondente é
int count = Integer.parseInt(args[0]);
rdi é o registrador usado para passar o primeiro argumento de uma função; se for Windows, então rdi = rdi[0], que corresponde a args[0]. Depois, chama java.lang.Integer.parseInt para analisar e obter um valor int, e então atribui o valor de retorno a uma variável de pilha sp_0x44.
int n1 = 0, n2 = 1, n3;
System.out.print(n1 + " " + n2);
Correspondendo a.
ret_1 = java.lang.StringConcatHelper.mix(1, 1)
ret_2 = java.lang.StringConcatHelper.mix(ret_1, 0)
sp_0x20 = java.io.PrintStream@0x554fe8
sp_0x18 = Class{[B}_1
tlab_0 = Class{[B}_1
tlab_0.length = ret_2<<ret_2>>32
sp_0x10 = tlab_0
ret_28 = ?java.lang.StringConcatHelper.prepend(tlab_0, " ", ret_2)
ret_29 = java.lang.StringConcatHelper.prepend(ret_28, sp_0x10, 0)
ret_30 = ?java.lang.StringConcatHelper.newString(sp_0x10, ret_29)
java.io.PrintStream.write(sp_0x20, ret_30)
No nosso código Java, a simples operação de concatenação de strings é na verdade convertida em três chamadas de função: StringConcatHelper.mix, StringConcatHelper.prepend e StringConcatHelper.newString. Entre elas, StringConcatHelper.mix calcula o comprimento da string concatenada, StringConcatHelper.prepend combina o array byte[] que carrega o conteúdo específico da string, e StringConcatHelper.newString gera um novo objeto String a partir do array byte[].
No código acima, vemos dois tipos de nomes de variáveis, sp_0x18 e tlab_0. Variáveis que começam com sp_ indicam variáveis alocadas na pilha, enquanto variáveis que começam com tlab_ indicam variáveis alocadas em Thread Local Allocation Buffers. Esta é apenas uma explicação da origem desses dois tipos de nomes de variáveis. No código restaurado, não há distinção entre esses dois tipos de variáveis. Para informações relacionadas a Thread Local Allocation Buffers, pesquise por conta própria.
Aqui atribuímos tlab_0 a Class{[B}_1. O significado de Class{[B}_1 é uma instância do tipo byte[]. [B representa o descritor Java para byte[], _1 indica que é a primeira variável desse tipo. Se houver variáveis subsequentes definidas para o tipo correspondente, o índice aumentará respectivamente, como Class{[B]}_2, Class{[B]}_3, etc. A mesma representação se aplica a outros tipos, como Class{java.lang.String}_1, Class{java.util.HashMap}_2, e assim por diante.
A lógica do código acima explica simplesmente a criação de uma instância de array byte[] e sua atribuição a tlab0. O comprimento do array é ret_2 << ret_2 >> 32. A razão pela qual o comprimento do array é ret_2 << ret_2 >> 32 é porque ao calcular o comprimento de uma String, é necessário converter o comprimento do array com base na codificação. Você pode consultar o código relevante em java.lang.String.java. Em seguida, a função prepend combina 0, 1 e espaços em tlab0, depois gera um novo objeto String ret_30 a partir de tlab_0 e o passa para a função java.io.PrintStream.write para saída de impressão. Na verdade, aqui os parâmetros restaurados pela função prepend não são muito precisos e suas posições também estão incorretas. Esta é uma área que precisa de melhorias adicionais mais tarde.
Após converter as duas linhas de código Java em lógica de execução real, ainda é bastante complexo. No futuro, pode ser simplificado analisando e integrando com base no código atualmente restaurado.
Continuando a avançar
for (int i = 2; i < count; ++i){
n3 = n1 + n2;
System.out.print(" " + n3);
n1 = n2;
n2 = n3;
}
System.out.println();
O correspondente é
if(sp_0x44>=3)
{
ret_7 = java.lang.StringConcatHelper.mix(1, 1)
tlab_1 = sp_0x18
tlab_1.length = ret_7<<ret_7>>32
sp_0x10 = " "
sp_0x8 = tlab_1
ret_22 = ?java.lang.StringConcatHelper.prepend(tlab_1, " ", ret_7)
ret_23 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_22)
rsi = ret_23
java.io.PrintStream.write(sp_0x20, ret_23)
rdi = 1
rdx = 1
rcx = 3
while(true)
{
if(sp_0x44<=rcx)
{
break
}
else
{
sp_0x34 = rcx
rdi = rdi+rdx
r9 = rdi
sp_0x30 = rdx
sp_0x2c = r9
ret_11 = java.lang.StringConcatHelper.mix(1, r9)
tlab_2 = sp_0x18
tlab_2.length = ret_11<<ret_11>>32
sp_0x8 = tlab_2
ret_17 = ?java.lang.StringConcatHelper.prepend(tlab_2, sp_0x10, ret_11)
ret_18 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_17)
rsi = ret_18
java.io.PrintStream.write(sp_0x20, ret_18)
rcx = sp_0x34+1
rdi = sp_0x30
rdx = sp_0x2c
}
}
}
java.io.PrintStream.newLine(sp_0x20, rsi)
return
sp_0x44 é o parâmetro que inserimos no programa, que é count. O loop for no código Java só será executado se count >= 3. Aqui, o loop for é transformado de volta em um loop while, essencialmente tendo a mesma semântica. Fora do loop while, o programa executa a lógica onde count=3. Se count <= 3, o programa completa a execução e não entrará no loop while novamente. Isso também pode ser uma otimização feita pelo GraalVM durante a compilação.
Vamos olhar novamente a condição de saída do loop.
if(sp_0x44<=rcx)
{
break
}
Isso corresponde a
i < count
Ao mesmo tempo, rcx também está acumulando durante cada processo de iteração.
sp_0x34 = rcx
rcx = sp_0x34+1
corresponde a
++i
Em seguida, vamos ver como a lógica de adição de números no corpo do loop é refletida no código restaurado. O código original é o seguinte:
for(......){
......
n3 = n1 + n2;
n1 = n2;
n2 = n3;
......
}
O código após a restauração é
while(true){
......
rdi = rdi+rdx -> n3 = n1 + n2
r9 = rdi -> r9 = n3
sp_0x30 = rdx -> sp_0x30 = n2
sp_0x2c = r9 -> sp_0x2c = n3
rdi = sp_0x30 -> n1 = sp_0x30 = n2
rdx = sp_0x2c -> n2 = sp_0x2c = n3
......
}
O outro código no corpo do loop realiza operações de concatenação e saída de strings como antes. O código restaurado basicamente reflete a lógica de execução do código original.
Melhorias adicionais necessárias
Atualmente, esta ferramenta é capaz de restaurar parcialmente o fluxo de controle do programa, alcançar algum nível de análise de fluxo de dados e restauração de nomes de funções. Para se tornar uma ferramenta completa e utilizável, ainda precisa alcançar o seguinte:
Restauração mais precisa de nomes de funções, parâmetros de funções e valores de retorno de funções
Restauração precisa de informações de objetos e campos
Inferência mais precisa de expressões e tipos de objetos
Integração e Simplificação de Instruções
Reflexões sobre proteção binária
O propósito deste projeto é explorar a viabilidade da engenharia reversa do NativeImage. Com base nas conquistas atuais, é viável fazer engenharia reversa do NativeImage, o que também traz desafios maiores para a proteção de código. Muitos desenvolvedores acreditam que compilar software em binários pode garantir a segurança, negligenciando a proteção do código binário. Para software escrito em C/C++, muitas ferramentas como o IDA já possuem excelentes efeitos de engenharia reversa, às vezes até expondo mais informações do que programas Java. Já vi até software distribuído em forma binária sem remover informações de símbolos de nomes de funções, o que é equivalente a estar completamente exposto.
Qualquer código é composto de lógica. Desde que contenha lógica, é possível restaurar sua lógica por meios reversos. A única diferença está na dificuldade da restauração. A proteção de código serve para maximizar a dificuldade dessa restauração.