Обратная разработка NativeImage
Восстановление и защита Java-кода — это давняя и часто обсуждаемая тема. Из-за формата байт-кода, используемого для хранения файлов классов Java, который содержит много метаинформации, его можно легко восстановить до исходного кода. Для защиты Java-кода индустрия применяла множество методов: обфускацию, шифрование байт-кода, JNI-защиту и так далее. Однако, независимо от используемого метода, по-прежнему существуют способы и средства для взлома.
Бинарная компиляция всегда считалась относительно эффективным методом защиты кода. Бинарная компиляция Java поддерживается как технология AOT (Ahead of Time), что означает предварительную компиляцию.
Однако из-за динамической природы языка Java бинарная компиляция должна решать такие проблемы, как рефлексия, динамическое проксирование, загрузка JNI и т.д., что создаёт множество трудностей. Поэтому долгое время не существовало зрелого, надёжного и широко применимого в продакшен-средах инструмента для AOT-компиляции Java. (Раньше существовал инструмент Excelsior JET, но похоже, что он был прекращён.)
В мае 2019 года Oracle выпустила GraalVM 19.0, мультиязычную виртуальную машину, которая стала первой версией, готовой для продакшена. GraalVM предоставляет инструмент NativeImage, который может выполнять AOT-компиляцию Java-программ. После нескольких лет развития NativeImage стал очень зрелым, и SpringBoot 3.0 может использовать его для компиляции всего проекта SpringBoot в исполняемый файл. Скомпилированный файл обладает быстрой скоростью запуска, низким потреблением памяти и отличной производительностью.
Итак, для Java-программ, вступивших в эру бинарной компиляции, так ли легко восстановить их код, как в эпоху байт-кода? Каковы характеристики бинарных файлов, скомпилированных NativeImage, и достаточна ли интенсивность бинарной компиляции для защиты важного кода?
Для исследования этих вопросов мы недавно разработали инструмент анализа NativeImage, который достиг определённого уровня обратной разработки.
Проект
https://github.com/vlinx-io/NativeImageAnalyzer
Генерация NativeImage
Сначала нам нужно сгенерировать NativeImage. NativeImage входит в состав GraalVM. Для загрузки GraalVM перейдите на https://www.graalvm.org/ и скачайте версию для Java 17. После загрузки установите переменную среды. Поскольку GraalVM содержит JDK, вы можете использовать его напрямую для выполнения команды java.
Добавьте $GRAALVM_HOME/bin в переменную среды, а затем выполните следующую команду для установки инструмента native-image:
gu install native-image
Простая Java-программа
Напишем простую Java-программу, например:
public class Hello {
public static void main(String[] args){
System.out.println("Hello World!");
}
}
Скомпилируйте и запустите вышеуказанную Java-программу:
javac Hello.java
java -cp . Hello
Вы получите следующий вывод:
Hello World!
Подготовка среды компиляции
Если вы пользователь Windows, сначала необходимо установить Visual Studio. Если вы пользователь Linux или macOS, необходимо предварительно установить такие инструменты, как gcc и clang.
Для пользователей Windows необходимо настроить переменную среды для Visual Studio перед выполнением команды native-image. Это можно сделать с помощью следующей команды:
"C:\Program Files (x86)\Microsoft Visual Studio\2017\Community\VC\Auxiliary\Build\vcvars64.bat"
Если путь установки и версия Visual Studio отличаются, скорректируйте соответствующую информацию о пути.
Компиляция с помощью native-image
Теперь используем команду native-image для компиляции вышеуказанной Java-программы в бинарный файл. Формат команды native-image такой же, как и формат команды java, и включает такие параметры, как -cp и -jar. Как вы используете команду java для запуска программы, так же используйте native-image для бинарной компиляции — просто замените команду java на native-image. Выполните команду:
native-image -cp . Hello
После некоторого времени компиляции (которая может потреблять больше CPU и памяти) вы получите скомпилированный бинарный файл. Имя выходного файла по умолчанию — строчное имя главного класса, в данном случае «hello». В Windows это будет «hello.exe». Используйте команду «file» для проверки типа файла:
file hello
hello: Mach-O 64-bit executable x86_64
Выполните этот файл, и его вывод будет таким же, как и при использовании java -cp . Hello:
Hello World!
Анализ NativeImage
Анализ с помощью IDA
Откройте скомпилированный файл hello в IDA, нажмите на Exports для просмотра таблицы символов. Вы увидите символ svm_code_section, адрес которого является точкой входа Java-функции Main.
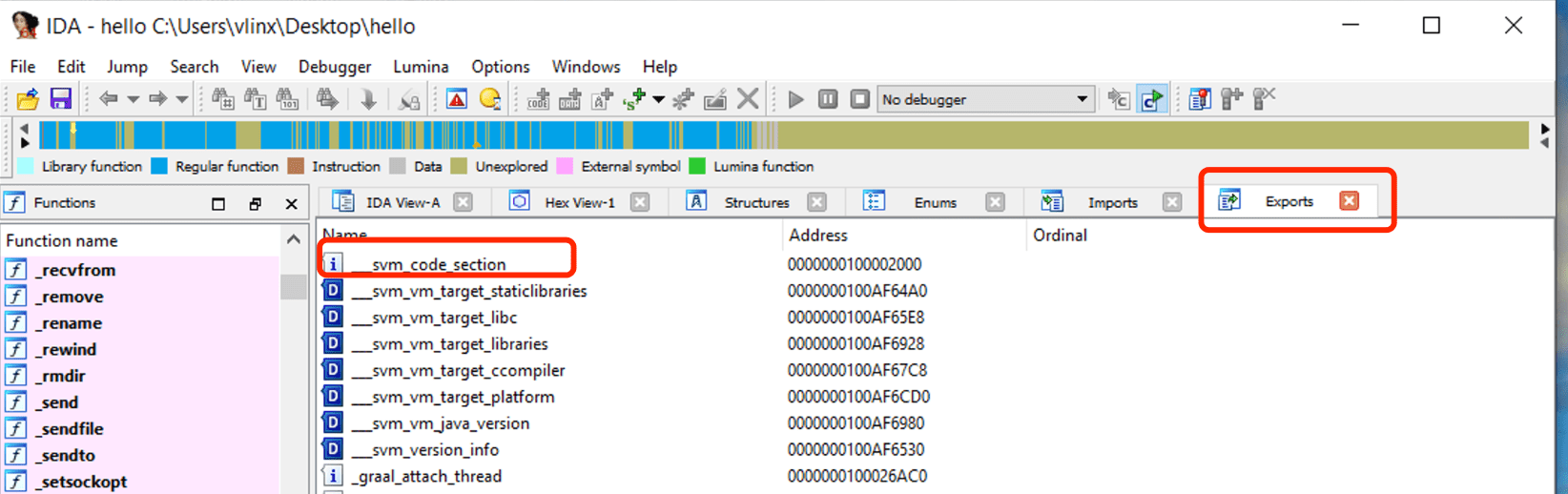
Перейдите по этому адресу для просмотра ассемблерного кода:
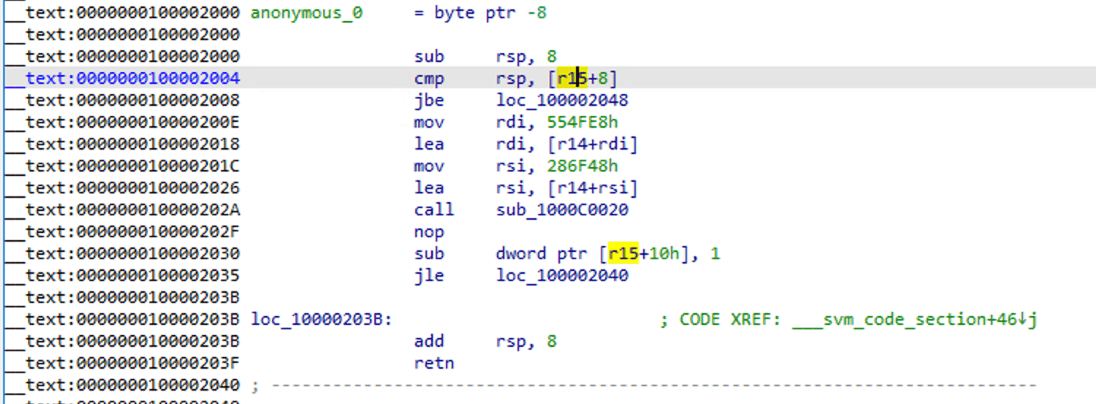
Видно, что код стал стандартной ассемблерной функцией. Используйте F5 для декомпиляции:
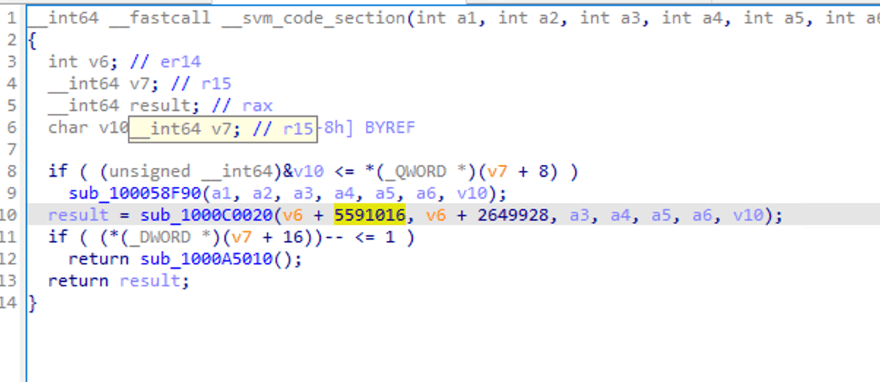
Можно увидеть некоторые вызовы функций и передаваемые параметры, но логику разобрать непросто.
При двойном клике на sub_1000C0020, чтобы заглянуть внутрь вызова функции, IDA сообщает о неудаче анализа.
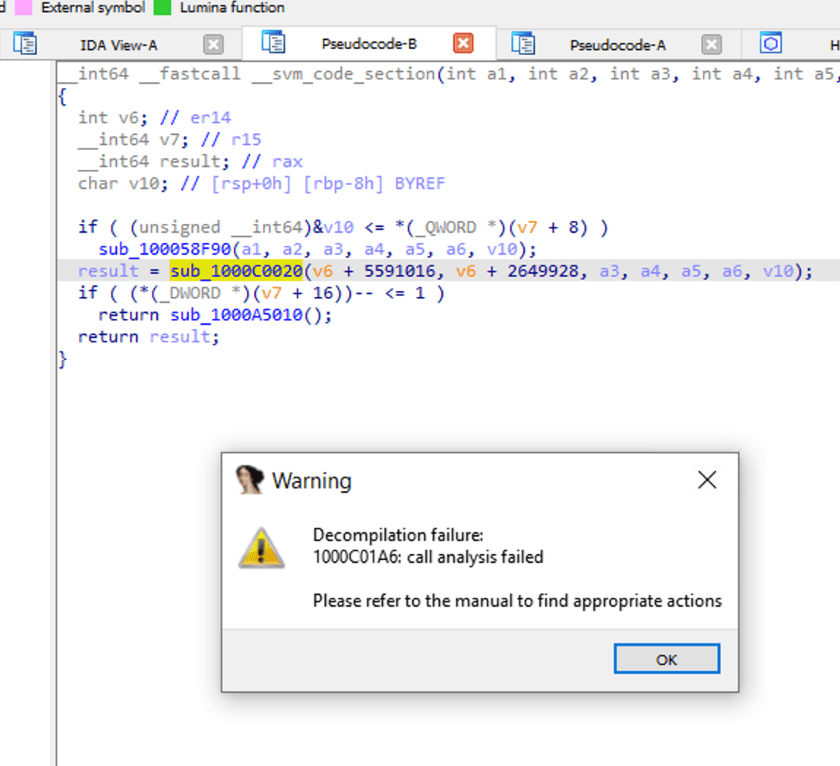
Логика декомпиляции NativeImage
Поскольку компиляция NativeImage основана на компиляции JVM, её также можно рассматривать как обёртку бинарного кода слоем VM-защиты. Поэтому такие инструменты, как IDA, не могут хорошо выполнить обратную разработку без соответствующей информации и целенаправленных мер обработки.
Однако, независимо от формата — байт-код или бинарная форма — некоторые базовые элементы выполнения JVM обязательно присутствуют: информация о классах, информация о полях, вызовы функций и передача параметров. Основываясь на этом подходе, разработанный мной инструмент анализа может достичь определённого уровня восстановления и, при дальнейшем улучшении, способен достичь высокой точности восстановления.
Анализ с помощью NativeImageAnalyzer
Перейдите на https://github.com/vlinx-io/NativeImageAnalyzer, чтобы загрузить NativeImageAnalyzer.
Выполните следующую команду для обратного анализа (в настоящее время анализируется только функция Main главного класса):
native-image-analyzer hello
Результат:
java.io.PrintStream.writeln(java.io.PrintStream@0x554fe8, "Hello World!", rcx)
return
Давайте снова посмотрим на оригинальный код:
public static void main(String[] args){
System.out.println("Hello World!");
}
Теперь посмотрим на определение System.out:
public static final PrintStream out = null;
Видно, что переменная 'out' класса System — это переменная типа PrintStream, и она является статической. Во время компиляции NativeImage напрямую компилирует экземпляр этого класса в область, называемую Heap, и бинарный код напрямую извлекает этот экземпляр из области Heap для вызова. Давайте посмотрим на восстановленный код:
java.io.PrintStream.writeln(java.io.PrintStream@0x554fe8, "Hello World!", rcx)
return
java.io.PrintStream@0x554fe8 — это экземпляр java.io.PrintStream, прочитанный из области Heap, расположенный по адресу памяти 0x554fe8.
Давайте также посмотрим на определение функции java.io.PrintStream.writeln:
private void writeln(String s) {
......
}
Здесь мы видим, что в функции writeln есть один аргумент типа String, но в восстановленном коде передаются три аргумента. Во-первых, writeln — это метод экземпляра класса, который скрывает один параметр this, указывающий на вызывающий объект, то есть первый переданный параметр java.io.PrintStream@0x554fe8. Что касается третьего параметра rcx — при анализе ассемблерного кода было определено, что эта функция вызывается с тремя параметрами. Однако из определения мы знаем, что на самом деле функция принимает только два параметра. Это область, которую нужно улучшить в инструменте в будущем.
Более сложная программа
Теперь проанализируем более сложную программу — вычисление последовательности Фибоначчи, со следующим кодом:
class Fibonacci {
public static void main(String[] args) {
int count = Integer.parseInt(args[0]);
int n1 = 0, n2 = 1, n3;
System.out.print(n1 + " " + n2);
for (int i = 2; i < count; ++i){
n3 = n1 + n2;
System.out.print(" " + n3);
n1 = n2;
n2 = n3;
}
System.out.println();
}
}
Компиляция и выполнение:
javac Fibonacci.java
native-image -cp . Fibonacci
./fibonacci 10
0 1 1 2 3 5 8 13 21 34
Код, полученный после восстановления с помощью NativeImageAnalyzer:
rdi = rdi[0]
ret_0 = java.lang.Integer.parseInt(rdi, 10)
sp_0x44 = ret_0
ret_1 = java.lang.StringConcatHelper.mix(1, 1)
ret_2 = java.lang.StringConcatHelper.mix(ret_1, 0)
sp_0x20 = java.io.PrintStream@0x554fe8
sp_0x18 = Class{[B}_1
tlab_0 = Class{[B}_1
tlab_0.length = ret_2<<ret_2>>32
sp_0x10 = tlab_0
ret_28 = ?java.lang.StringConcatHelper.prepend(tlab_0, " ", ret_2)
ret_29 = java.lang.StringConcatHelper.prepend(ret_28, sp_0x10, 0)
ret_30 = ?java.lang.StringConcatHelper.newString(sp_0x10, ret_29)
java.io.PrintStream.write(sp_0x20, ret_30)
if(sp_0x44>=3)
{
ret_7 = java.lang.StringConcatHelper.mix(1, 1)
tlab_1 = sp_0x18
tlab_1.length = ret_7<<ret_7>>32
sp_0x10 = " "
sp_0x8 = tlab_1
ret_22 = ?java.lang.StringConcatHelper.prepend(tlab_1, " ", ret_7)
ret_23 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_22)
rsi = ret_23
java.io.PrintStream.write(sp_0x20, ret_23)
rdi = 1
rdx = 1
rcx = 3
while(true)
{
if(sp_0x44<=rcx)
{
break
}
else
{
sp_0x34 = rcx
rdi = rdi+rdx
r9 = rdi
sp_0x30 = rdx
sp_0x2c = r9
ret_11 = java.lang.StringConcatHelper.mix(1, r9)
tlab_2 = sp_0x18
tlab_2.length = ret_11<<ret_11>>32
sp_0x8 = tlab_2
ret_17 = ?java.lang.StringConcatHelper.prepend(tlab_2, sp_0x10, ret_11)
ret_18 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_17)
rsi = ret_18
java.io.PrintStream.write(sp_0x20, ret_18)
rcx = sp_0x34+1
rdi = sp_0x30
rdx = sp_0x2c
}
}
}
java.io.PrintStream.newLine(sp_0x20, rsi)
return
Сравним восстановленный код с оригинальным.
rdi = rdi[0]
ret_0 = java.lang.Integer.parseInt(rdi, 10)
sp_0x44 = ret_0
Это соответствует:
int count = Integer.parseInt(args[0]);
rdi — это регистр, используемый для передачи первого аргумента функции. Если это Windows, то rdi = rdi[0] соответствует args[0]. Затем вызывается java.lang.Integer.parseInt для разбора и получения значения int, после чего возвращаемое значение присваивается стековой переменной sp_0x44.
int n1 = 0, n2 = 1, n3;
System.out.print(n1 + " " + n2);
Соответствует:
ret_1 = java.lang.StringConcatHelper.mix(1, 1)
ret_2 = java.lang.StringConcatHelper.mix(ret_1, 0)
sp_0x20 = java.io.PrintStream@0x554fe8
sp_0x18 = Class{[B}_1
tlab_0 = Class{[B}_1
tlab_0.length = ret_2<<ret_2>>32
sp_0x10 = tlab_0
ret_28 = ?java.lang.StringConcatHelper.prepend(tlab_0, " ", ret_2)
ret_29 = java.lang.StringConcatHelper.prepend(ret_28, sp_0x10, 0)
ret_30 = ?java.lang.StringConcatHelper.newString(sp_0x10, ret_29)
java.io.PrintStream.write(sp_0x20, ret_30)
В нашем Java-коде простая операция конкатенации строк фактически преобразуется в три вызова функций: StringConcatHelper.mix, StringConcatHelper.prepend и StringConcatHelper.newString. Из них StringConcatHelper.mix вычисляет длину конкатенированной строки, StringConcatHelper.prepend объединяет массив byte[], содержащий конкретное содержимое строки, а StringConcatHelper.newString создаёт новый объект String из массива byte[].
В приведённом выше коде мы видим два типа имён переменных: sp_0x18 и tlab_0. Переменные, начинающиеся с sp_, обозначают переменные, размещённые в стеке, а переменные, начинающиеся с tlab_, обозначают переменные, размещённые в Thread Local Allocation Buffers. Это лишь объяснение происхождения этих двух типов имён переменных. В восстановленном коде различий между этими двумя типами переменных нет. Информацию о Thread Local Allocation Buffers вы можете найти самостоятельно.
Здесь мы присваиваем tlab_0 значение Class{[B}_1. Значение Class{[B}_1 — это экземпляр типа byte[]. [B представляет Java-дескриптор byte[], _1 указывает, что это первая переменная данного типа. Если впоследствии будут определены другие переменные соответствующего типа, индекс увеличится, например, Class{[B]}_2, Class{[B]}_3 и т.д. Такое же представление применяется к другим типам, например, Class{java.lang.String}_1, Class{java.util.HashMap}_2 и т.д.
Логика приведённого выше кода описывает простое создание экземпляра массива byte[] и присваивание его tlab0. Длина массива — ret_2 << ret_2 >> 32. Причина такого вычисления длины массива заключается в том, что при вычислении длины String необходимо преобразовать длину массива в соответствии с кодировкой. Подробнее см. соответствующий код в java.lang.String.java. Далее функция prepend объединяет 0, 1 и пробелы в tlab0, затем из tlab_0 создаётся новый объект String ret_30, который передаётся функции java.io.PrintStream.write для вывода на печать. На самом деле параметры, восстановленные для функции prepend, не очень точны, и их позиции также некорректны. Это область, требующая дальнейшего улучшения.
После преобразования двух строк Java-кода в фактическую логику выполнения результат оказывается довольно сложным. В будущем его можно упростить путём анализа и интеграции на основе текущего восстановленного кода.
Продолжим:
for (int i = 2; i < count; ++i){
n3 = n1 + n2;
System.out.print(" " + n3);
n1 = n2;
n2 = n3;
}
System.out.println();
Соответствует:
if(sp_0x44>=3)
{
ret_7 = java.lang.StringConcatHelper.mix(1, 1)
tlab_1 = sp_0x18
tlab_1.length = ret_7<<ret_7>>32
sp_0x10 = " "
sp_0x8 = tlab_1
ret_22 = ?java.lang.StringConcatHelper.prepend(tlab_1, " ", ret_7)
ret_23 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_22)
rsi = ret_23
java.io.PrintStream.write(sp_0x20, ret_23)
rdi = 1
rdx = 1
rcx = 3
while(true)
{
if(sp_0x44<=rcx)
{
break
}
else
{
sp_0x34 = rcx
rdi = rdi+rdx
r9 = rdi
sp_0x30 = rdx
sp_0x2c = r9
ret_11 = java.lang.StringConcatHelper.mix(1, r9)
tlab_2 = sp_0x18
tlab_2.length = ret_11<<ret_11>>32
sp_0x8 = tlab_2
ret_17 = ?java.lang.StringConcatHelper.prepend(tlab_2, sp_0x10, ret_11)
ret_18 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_17)
rsi = ret_18
java.io.PrintStream.write(sp_0x20, ret_18)
rcx = sp_0x34+1
rdi = sp_0x30
rdx = sp_0x2c
}
}
}
java.io.PrintStream.newLine(sp_0x20, rsi)
return
sp_0x44 — это параметр, который мы передаём программе, то есть count. Цикл for в Java-коде выполняется только при count >= 3. Здесь цикл for преобразован обратно в цикл while, семантически они эквивалентны. За пределами цикла while программа выполняет логику при count=3. Если count <= 3, программа завершает выполнение и не входит в цикл while снова. Это также может быть оптимизацией, выполненной GraalVM при компиляции.
Давайте рассмотрим условие выхода из цикла:
if(sp_0x44<=rcx)
{
break
}
Это соответствует:
i < count
Одновременно rcx также накапливается в каждой итерации:
sp_0x34 = rcx
rcx = sp_0x34+1
Соответствует:
++i
Далее рассмотрим, как логика сложения чисел в теле цикла отражена в восстановленном коде. Оригинальный код:
for(......){
......
n3 = n1 + n2;
n1 = n2;
n2 = n3;
......
}
Восстановленный код:
while(true){
......
rdi = rdi+rdx -> n3 = n1 + n2
r9 = rdi -> r9 = n3
sp_0x30 = rdx -> sp_0x30 = n2
sp_0x2c = r9 -> sp_0x2c = n3
rdi = sp_0x30 -> n1 = sp_0x30 = n2
rdx = sp_0x2c -> n2 = sp_0x2c = n3
......
}
Остальной код в теле цикла выполняет операции конкатенации строк и вывода, как и ранее. Восстановленный код в целом отражает логику выполнения оригинального кода.
Необходимые дальнейшие улучшения
В настоящее время этот инструмент способен частично восстановить поток управления программ, выполнить некоторый уровень анализа потока данных и восстановить имена функций. Чтобы стать полным и пригодным для использования инструментом, ему ещё необходимо достичь следующего:
Более точное восстановление имён функций, параметров и возвращаемых значений
Точное восстановление информации об объектах и полях
Более точный вывод типов выражений и объектов
Интеграция и упрощение инструкций
Размышления о бинарной защите
Цель этого проекта — исследовать возможность обратной разработки NativeImage. На основе текущих достижений обратная разработка NativeImage вполне осуществима, что также создаёт повышенные требования к защите кода. Многие разработчики считают, что компиляция программного обеспечения в бинарные файлы гарантирует безопасность, пренебрегая защитой бинарного кода. Для программного обеспечения, написанного на C/C++, многие инструменты, такие как IDA, уже обеспечивают отличные результаты обратной разработки, иногда раскрывая даже больше информации, чем Java-программы. Я даже видел программное обеспечение, распространяемое в бинарной форме, без удаления символьной информации имён функций — это равносильно работе без какой-либо защиты.
Любой код состоит из логики. Пока он содержит логику, его логику можно восстановить с помощью обратных методов. Единственная разница заключается в сложности восстановления. Защита кода направлена на максимальное увеличение сложности такого восстановления.