NativeImage 逆向工程
還原和保護 Java 程式碼是一個由來已久且經常被討論的議題。由於 Java class 檔案採用的位元組碼格式包含大量的中繼資訊,可以輕鬆還原為原始碼。為了保護 Java 程式碼,業界採用了許多方法,例如混淆、位元組碼加密、JNI 保護等。然而,無論使用哪種方法,仍然有途徑和手段可以破解。
二進位編譯一直被認為是相對有效的程式碼保護方法。Java 的二進位編譯作為 AOT(Ahead of Time,預先編譯)技術獲得支援。
然而,由於 Java 語言的動態特性,二進位編譯需要處理反射、動態代理、JNI 載入等問題,這帶來了許多困難。因此,長期以來,Java 一直缺乏一個成熟、可靠且適用性廣的 AOT 編譯工具可以廣泛應用於生產環境。(曾經有一個名為 Excelsior JET 的工具,但似乎已經停止營運了。)
2019 年 5 月,Oracle 發佈了 GraalVM 19.0,這是一個支援多種語言的虛擬機,也是其第一個可用於生產環境的版本。GraalVM 提供了 NativeImage 工具,可以實現 Java 程式的 AOT 編譯。經過多年的發展,NativeImage 現在已經非常成熟,SpringBoot 3.0 可以使用它將整個 SpringBoot 專案編譯成可執行檔。編譯後的檔案啟動速度快、記憶體使用低且效能優異。
那麼,對於已經進入二進位編譯時代的 Java 程式,其程式碼是否仍然像位元組碼時代那樣容易被逆向?NativeImage 編譯的二進位檔案有什麼特點,二進位編譯的強度是否足以保護重要的程式碼?
為了探索這些問題,我們最近開發了一個 NativeImage 分析工具,已經實現了一定程度的逆向效果。
專案
https://github.com/vlinx-io/NativeImageAnalyzer
產生 NativeImage
首先,我們需要產生一個 NativeImage。NativeImage 來自 GraalVM。要下載 GraalVM,請前往 https://www.graalvm.org/ 並下載 Java 17 版本。下載後,設定環境變數。由於 GraalVM 包含 JDK,您可以直接使用它來執行 java 命令。
將 $GRAALVM_HOME/bin 加入環境變數,然後執行以下命令安裝 native-image 工具
gu install native-image
一個簡單的 Java 程式
編寫一個簡單的 Java 程式,例如:
public class Hello {
public static void main(String[] args){
System.out.println("Hello World!");
}
}
編譯並執行上述 Java 程式:
javac Hello.java
java -cp . Hello
您將得到以下輸出:
Hello World!
編譯環境準備
如果您是 Windows 使用者,需要先安裝 Visual Studio。如果您是 Linux 或 macOS 使用者,需要事先安裝 gcc 和 clang 等工具。
對於 Windows 使用者,您需要在執行 native-image 命令之前設定 Visual Studio 的環境變數。您可以使用以下命令進行設定:
"C:\Program Files (x86)\Microsoft Visual Studio\2017\Community\VC\Auxiliary\Build\vcvars64.bat"
如果 Visual Studio 的安裝路徑和版本不同,請相應調整相關路徑資訊。
使用 native-image 編譯
現在使用 native-image 命令將上述 Java 程式編譯為二進位檔案。native-image 命令的格式與 java 命令格式相同,同樣有 -cp、-jar 這些參數,如何使用 java 命令執行程式,就用相同的方式進行二進位編譯,只需將命令從 java 替換為 native-image。執行以下命令
native-image -cp . Hello
經過一段時間的編譯(可能會消耗較多的 CPU 和記憶體),您可以得到一個編譯好的二進位檔案,輸出檔案名稱預設為主類別名稱的小寫,在本例中為「hello」。如果在 Windows 下,則為「hello.exe」。使用「file」命令檢查此檔案的類型,可以看到它確實是一個二進位檔案。
file hello
hello: Mach-O 64-bit executable x86_64
執行此檔案,其輸出與之前使用 java -cp . Hello 的結果一致
Hello World!
分析 NativeImage
使用 IDA 進行分析
使用 IDA 開啟上述步驟編譯的 hello,點擊 Exports 查看符號表,可以看到符號 svm_code_section,其地址就是 Java Main 函式的入口地址。
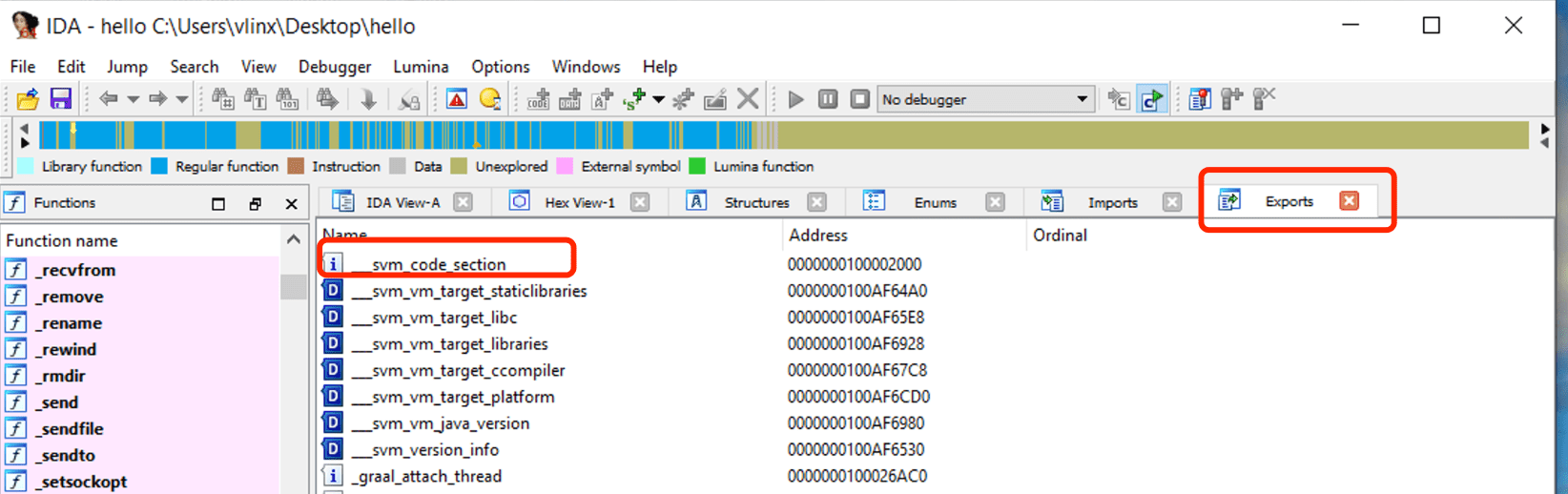
導航到此地址查看組合語言程式碼
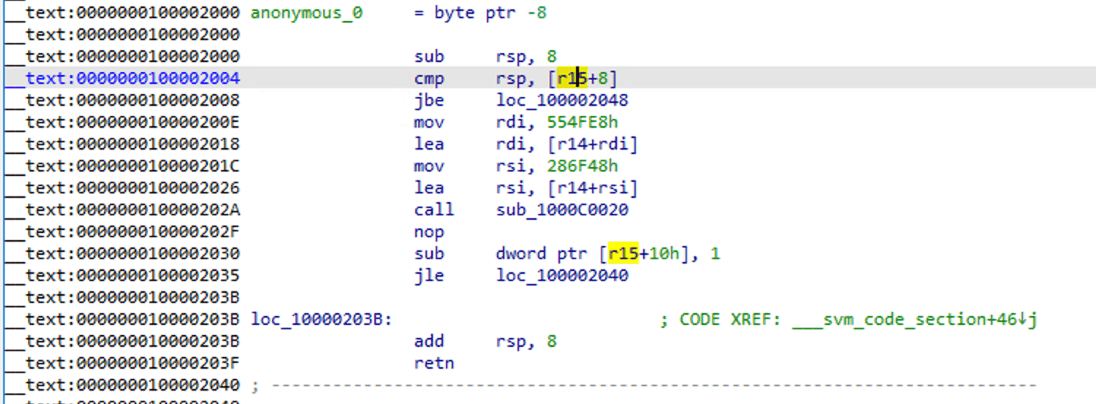
可以看到它已經變成了標準的組合語言函式,使用 F5 進行反編譯
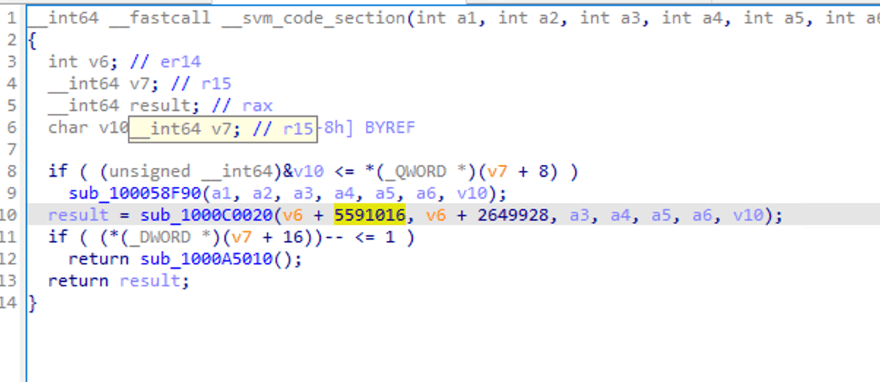
可以看到一些函式呼叫和傳遞的參數,但不容易看出邏輯。
當我們雙擊 sub_1000C0020 時,讓我們看看函式呼叫的內部。IDA 提示分析失敗。
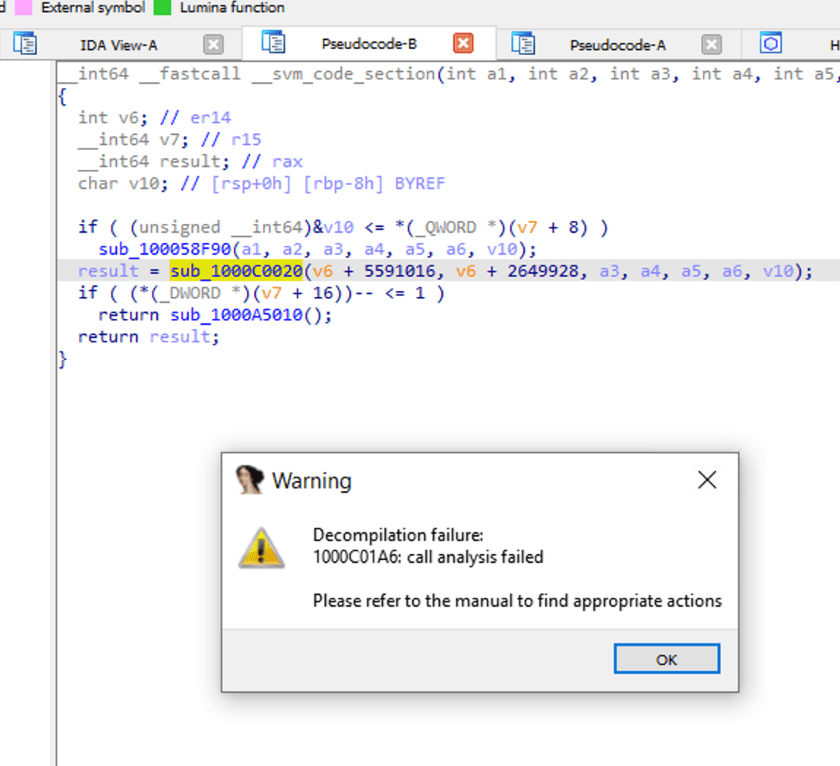
NativeImage 的反編譯邏輯
因為 NativeImage 的編譯是基於 JVM 編譯的,也可以理解為用一層 VM 保護包裹了二進位程式碼。因此,在缺乏相應資訊和針對性處理措施的情況下,IDA 等工具無法很好地對其進行逆向工程。
然而,無論是位元組碼還是二進位形式,JVM 執行的一些基本元素必然存在,例如類別資訊、欄位資訊、函式呼叫和參數傳遞。基於這種思路,我開發的分析工具能夠實現一定程度的還原效果,並且經過進一步改進,有能力實現較高的還原準確度。
使用 NativeImageAnalyzer 進行分析
前往 https://github.com/vlinx-io/NativeImageAnalyzer 下載 NativeImageAnalyzer
執行以下命令進行逆向分析,目前僅分析主類別的 Main 函式
native-image-analyzer hello
輸出如下
java.io.PrintStream.writeln(java.io.PrintStream@0x554fe8, "Hello World!", rcx)
return
讓我們再看一下原始碼。
public static void main(String[] args){
System.out.println("Hello World!");
}
現在讓我們看一下 System.out 的定義。
public static final PrintStream out = null;
可以看到 System 類別的 'out' 變數是 PrintStream 類型的變數,且是靜態變數。在編譯過程中,NativeImage 直接將此類別的實例編譯到名為 Heap 的區域中,二進位程式碼直接從 Heap 區域取得此實例進行呼叫。讓我們看看還原後的程式碼。
java.io.PrintStream.writeln(java.io.PrintStream@0x554fe8, "Hello World!", rcx)
return
這些 java.io.PrintStream@0x554fe8 就是從 Heap 區域讀取的 java.io.PrintStream 實例變數,位於記憶體位址 0x554fe8。
我們再來看一下 java.io.PrintStream.writeln 函式的定義
private void writeln(String s) {
......
}
這裡我們可以看到 writeln 函式中有一個 String 參數,但在還原的程式碼中,為什麼傳遞了三個參數?首先 writeln 是一個類別成員方法,隱藏了一個 this,此變數指向呼叫者,就是傳遞的第一個參數 java.io.PrintStream@0x554fe8。至於第三個參數 rcx,是因為在分析組合語言程式碼的過程中,判斷此函式是用三個參數呼叫的。然而,檢查定義後,我們知道此函式實際上只呼叫兩個參數。這也是此工具未來需要改進的地方。
一個更複雜的程式
我們現在將分析一個更複雜的程式,例如計算費波那契數列,程式碼如下
class Fibonacci {
public static void main(String[] args) {
int count = Integer.parseInt(args[0]);
int n1 = 0, n2 = 1, n3;
System.out.print(n1 + " " + n2);
for (int i = 2; i < count; ++i){
n3 = n1 + n2;
System.out.print(" " + n3);
n1 = n2;
n2 = n3;
}
System.out.println();
}
}
編譯並執行
javac Fibonacci.java
native-image -cp . Fibonacci
./fibonacci 10
0 1 1 2 3 5 8 13 21 34
使用 NativeImageAnalyzer 還原的程式碼如下
rdi = rdi[0]
ret_0 = java.lang.Integer.parseInt(rdi, 10)
sp_0x44 = ret_0
ret_1 = java.lang.StringConcatHelper.mix(1, 1)
ret_2 = java.lang.StringConcatHelper.mix(ret_1, 0)
sp_0x20 = java.io.PrintStream@0x554fe8
sp_0x18 = Class{[B}_1
tlab_0 = Class{[B}_1
tlab_0.length = ret_2<<ret_2>>32
sp_0x10 = tlab_0
ret_28 = ?java.lang.StringConcatHelper.prepend(tlab_0, " ", ret_2)
ret_29 = java.lang.StringConcatHelper.prepend(ret_28, sp_0x10, 0)
ret_30 = ?java.lang.StringConcatHelper.newString(sp_0x10, ret_29)
java.io.PrintStream.write(sp_0x20, ret_30)
if(sp_0x44>=3)
{
ret_7 = java.lang.StringConcatHelper.mix(1, 1)
tlab_1 = sp_0x18
tlab_1.length = ret_7<<ret_7>>32
sp_0x10 = " "
sp_0x8 = tlab_1
ret_22 = ?java.lang.StringConcatHelper.prepend(tlab_1, " ", ret_7)
ret_23 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_22)
rsi = ret_23
java.io.PrintStream.write(sp_0x20, ret_23)
rdi = 1
rdx = 1
rcx = 3
while(true)
{
if(sp_0x44<=rcx)
{
break
}
else
{
sp_0x34 = rcx
rdi = rdi+rdx
r9 = rdi
sp_0x30 = rdx
sp_0x2c = r9
ret_11 = java.lang.StringConcatHelper.mix(1, r9)
tlab_2 = sp_0x18
tlab_2.length = ret_11<<ret_11>>32
sp_0x8 = tlab_2
ret_17 = ?java.lang.StringConcatHelper.prepend(tlab_2, sp_0x10, ret_11)
ret_18 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_17)
rsi = ret_18
java.io.PrintStream.write(sp_0x20, ret_18)
rcx = sp_0x34+1
rdi = sp_0x30
rdx = sp_0x2c
}
}
}
java.io.PrintStream.newLine(sp_0x20, rsi)
return
將還原的程式碼與原始碼進行比較。
rdi = rdi[0]
ret_0 = java.lang.Integer.parseInt(rdi, 10)
sp_0x44 = ret_0
對應的是
int count = Integer.parseInt(args[0]);
rdi 是用於傳遞函式第一個參數的暫存器,如果是 Windows,則 rdi = rdi[0],對應 args[0],然後呼叫 java.lang.Integer.parseInt 解析並獲得一個 int 值,再將回傳值賦給堆疊變數 sp_0x44。
int n1 = 0, n2 = 1, n3;
System.out.print(n1 + " " + n2);
對應的是
ret_1 = java.lang.StringConcatHelper.mix(1, 1)
ret_2 = java.lang.StringConcatHelper.mix(ret_1, 0)
sp_0x20 = java.io.PrintStream@0x554fe8
sp_0x18 = Class{[B}_1
tlab_0 = Class{[B}_1
tlab_0.length = ret_2<<ret_2>>32
sp_0x10 = tlab_0
ret_28 = ?java.lang.StringConcatHelper.prepend(tlab_0, " ", ret_2)
ret_29 = java.lang.StringConcatHelper.prepend(ret_28, sp_0x10, 0)
ret_30 = ?java.lang.StringConcatHelper.newString(sp_0x10, ret_29)
java.io.PrintStream.write(sp_0x20, ret_30)
在我們的 Java 程式碼中,簡單的字串串接操作實際上被轉換為三個函式呼叫:StringConcatHelper.mix、StringConcatHelper.prepend 和 StringConcatHelper.newString。其中,StringConcatHelper.mix 計算串接後字串的長度,StringConcatHelper.prepend 將攜帶具體字串內容的 byte[] 陣列組合在一起,StringConcatHelper.newString 從 byte[] 陣列產生新的 String 物件。
在上述程式碼中,我們看到兩種類型的變數名稱:sp_0x18 和 tlab_0。以 sp_ 開頭的變數表示在堆疊上分配的變數,而以 tlab_ 開頭的變數表示在執行緒本地分配緩衝區(Thread Local Allocation Buffers)上分配的變數。這只是解釋這兩類變數名稱的來源。在還原的程式碼中,這兩類變數之間沒有區別。有關執行緒本地分配緩衝區的相關資訊,請自行搜尋。
這裡我們將 tlab_0 賦值為 Class{[B}_1。Class{[B}_1 的含義是 byte[] 類型的實例。[B 表示 byte[] 的 Java 描述符,_1 表示這是該類型的第一個變數。如果後續有對應類型的變數定義,索引將相應增加,例如 Class{[B]}_2、Class{[B]}_3 等。相同的表示方式適用於其他類型,例如 Class{java.lang.String}_1、Class{java.util.HashMap}_2 等。
上述程式碼的邏輯簡單解釋就是建立一個 byte[] 陣列實例並賦值給 tlab0。陣列的長度為 ret_2 << ret_2 >> 32。陣列長度為 ret_2 << ret_2 >> 32 的原因是在計算 String 長度時,需要根據編碼轉換陣列長度。您可以參考 java.lang.String.java 中的相關程式碼。接著,prepend 函式將 0、1 和空格組合到 tlab0 中,然後從 tlab_0 產生新的 String 物件 ret_30 並傳遞給 java.io.PrintStream.write 函式進行列印輸出。實際上,這裡 prepend 函式還原的參數不太準確,位置也不正確。這也是此工具未來需要進一步改進的地方。
在將兩行 Java 程式碼轉換為實際執行邏輯後,仍然相當複雜。未來可以在目前還原程式碼的基礎上,透過分析和整合來簡化。
繼續往前看
for (int i = 2; i < count; ++i){
n3 = n1 + n2;
System.out.print(" " + n3);
n1 = n2;
n2 = n3;
}
System.out.println();
對應的是
if(sp_0x44>=3)
{
ret_7 = java.lang.StringConcatHelper.mix(1, 1)
tlab_1 = sp_0x18
tlab_1.length = ret_7<<ret_7>>32
sp_0x10 = " "
sp_0x8 = tlab_1
ret_22 = ?java.lang.StringConcatHelper.prepend(tlab_1, " ", ret_7)
ret_23 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_22)
rsi = ret_23
java.io.PrintStream.write(sp_0x20, ret_23)
rdi = 1
rdx = 1
rcx = 3
while(true)
{
if(sp_0x44<=rcx)
{
break
}
else
{
sp_0x34 = rcx
rdi = rdi+rdx
r9 = rdi
sp_0x30 = rdx
sp_0x2c = r9
ret_11 = java.lang.StringConcatHelper.mix(1, r9)
tlab_2 = sp_0x18
tlab_2.length = ret_11<<ret_11>>32
sp_0x8 = tlab_2
ret_17 = ?java.lang.StringConcatHelper.prepend(tlab_2, sp_0x10, ret_11)
ret_18 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_17)
rsi = ret_18
java.io.PrintStream.write(sp_0x20, ret_18)
rcx = sp_0x34+1
rdi = sp_0x30
rdx = sp_0x2c
}
}
}
java.io.PrintStream.newLine(sp_0x20, rsi)
return
sp_0x44 是我們輸入給程式的參數,即 count。Java 程式碼中的 for 迴圈只有在 count >= 3 時才會執行。這裡,for 迴圈被轉換回 while 迴圈,本質上具有相同的語義。在 while 迴圈之外,程式執行 count=3 時的邏輯。如果 count <= 3,程式完成執行而不會再次進入 while 迴圈。這可能也是 GraalVM 在編譯過程中進行的最佳化。
讓我們再看看迴圈的退出條件。
if(sp_0x44<=rcx)
{
break
}
這對應的是
i < count
同時,rcx 也在每次迭代過程中累加。
sp_0x34 = rcx
rcx = sp_0x34+1
對應的是
++i
接下來,讓我們看看迴圈體中的數字加法邏輯如何在還原的程式碼中體現。原始碼如下:
for(......){
......
n3 = n1 + n2;
n1 = n2;
n2 = n3;
......
}
還原後的程式碼是
while(true){
......
rdi = rdi+rdx -> n3 = n1 + n2
r9 = rdi -> r9 = n3
sp_0x30 = rdx -> sp_0x30 = n2
sp_0x2c = r9 -> sp_0x2c = n3
rdi = sp_0x30 -> n1 = sp_0x30 = n2
rdx = sp_0x2c -> n2 = sp_0x2c = n3
......
}
迴圈體中的其他程式碼與之前一樣執行字串串接和輸出操作。還原的程式碼基本反映了原始碼的執行邏輯。
仍需進一步改進
目前,此工具能夠部分還原程式控制流程,實現一定程度的資料流分析和函式名稱還原。要成為一個完整且可用的工具,仍然需要完成以下工作:
更準確的函式名稱、函式參數和函式回傳值還原
準確的物件資訊和欄位還原
更準確的表達式和物件類型推斷
語句整合和簡化
對二進位保護的思考
此專案的目的是探索 NativeImage 逆向工程的可行性。基於目前的成果,逆向工程 NativeImage 是可行的,這也對程式碼保護帶來了更高的挑戰。許多開發者認為將軟體編譯為二進位就能保證安全,從而忽略了對二進位程式碼的保護。對於使用 C/C++ 編寫的軟體,IDA 等許多工具已經具有出色的逆向工程效果,有時甚至暴露的資訊比 Java 程式還多。我甚至見過一些以二進位形式發佈的軟體沒有移除函式名稱的符號資訊,這等同於裸奔。
任何程式碼都是由邏輯組成的。只要包含邏輯,就有可能透過逆向手段還原其邏輯。唯一的區別在於還原的難度。程式碼保護就是要最大化這種還原的難度。