NativeImage 逆向工程
还原和保护 Java 代码是一个老生常谈的问题。由于 Java class 文件采用的字节码格式包含大量元信息,因此很容易被还原为原始代码。为了保护 Java 代码,业界采用了许多方法,如混淆、字节码加密、JNI 保护等。然而,无论使用哪种方法,都仍然有方法和手段可以破解。
二进制编译一直被认为是相对有效的代码保护方法。Java 的二进制编译以 AOT (Ahead of Time) 技术的形式得到支持,即预编译。
然而,由于 Java 语言的动态特性,二进制编译需要处理反射、动态代理、JNI 加载等问题,这带来了许多困难。因此,在很长一段时间内,Java 一直缺乏一个成熟、可靠且适应性强的 AOT 编译工具,可以广泛应用于生产环境。(以前有一个叫做 Excelsior JET 的工具,但似乎已经停止运营了。)
2019 年 5 月,Oracle 发布了 GraalVM 19.0,一个支持多语言的虚拟机,这是其第一个生产就绪版本。GraalVM 提供了 NativeImage 工具,可以实现 Java 程序的 AOT 编译。经过几年的发展,NativeImage 现在已经非常成熟,SpringBoot 3.0 可以使用它将整个 SpringBoot 项目编译为可执行文件。编译后的文件启动速度快,内存使用少,性能优秀。
那么,对于已经进入二进制编译时代的 Java 程序,其代码是否仍然像在字节码时代那样容易被逆向?NativeImage 编译的二进制文件有什么特点,二进制编译的强度是否足以保护重要代码?
为了探索这些问题,我们最近开发了一个 NativeImage 分析工具,已经实现了一定程度的逆向效果。
项目
https://github.com/vlinx-io/NativeImageAnalyzer
生成 NativeImage
首先,我们需要生成一个 NativeImage。NativeImage 来自 GraalVM。下载 GraalVM 请访问 https://www.graalvm.org/,下载 Java 17 版本。下载后设置环境变量。由于 GraalVM 包含 JDK,您可以直接使用它执行 java 命令。
将 $GRAALVM_HOME/bin 添加到环境变量,然后执行以下命令安装 native-image 工具
gu install native-image
一个简单的 Java 程序
编写一个简单的 Java 程序,例如:
public class Hello {
public static void main(String[] args){
System.out.println("Hello World!");
}
}
编译并运行上述 Java 程序:
javac Hello.java
java -cp . Hello
将得到以下输出:
Hello World!
编译环境准备
Windows 用户需要先安装 Visual Studio。Linux 或 macOS 用户需要预先安装 gcc、clang 等工具。
Windows 用户在执行 native-image 命令前需要设置 Visual Studio 的环境变量。可以使用以下命令设置:
"C:\Program Files (x86)\Microsoft Visual Studio\2017\Community\VC\Auxiliary\Build\vcvars64.bat"
如果 Visual Studio 的安装路径和版本不同,请相应调整路径信息。
使用 native-image 编译
现在使用 native-image 命令将上述 Java 程序编译为二进制文件。native-image 命令的格式与 java 命令格式相同,同样具有 -cp、-jar 等参数。如何使用 java 命令执行程序,就用同样的方式进行二进制编译,只需将命令从 java 替换为 native-image。执行以下命令
native-image -cp . Hello
编译需要一段时间,可能消耗较多 CPU 和内存。您可以获得一个编译后的二进制文件,输出文件名默认为主类名的小写,在本例中为 "hello"。如果在 Windows 下则为 "hello.exe"。使用 "file" 命令检查文件类型,可以看到它确实是一个二进制文件。
file hello
hello: Mach-O 64-bit executable x86_64
执行此文件,其输出与之前使用 java -cp . Hello 的结果一致
Hello World!
分析 NativeImage
使用 IDA 分析
使用 IDA 打开上述步骤编译的 hello,点击 Exports 查看符号表,可以看到符号 svm_code_section,其地址就是 Java Main 函数的入口地址。
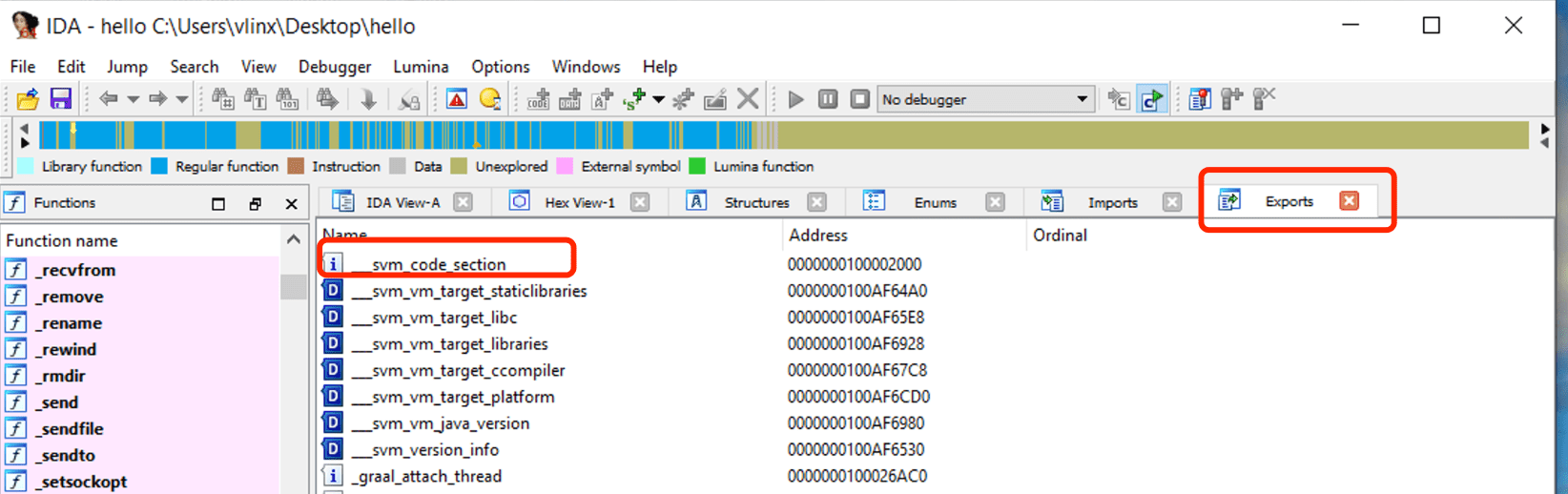
导航到该地址查看汇编代码
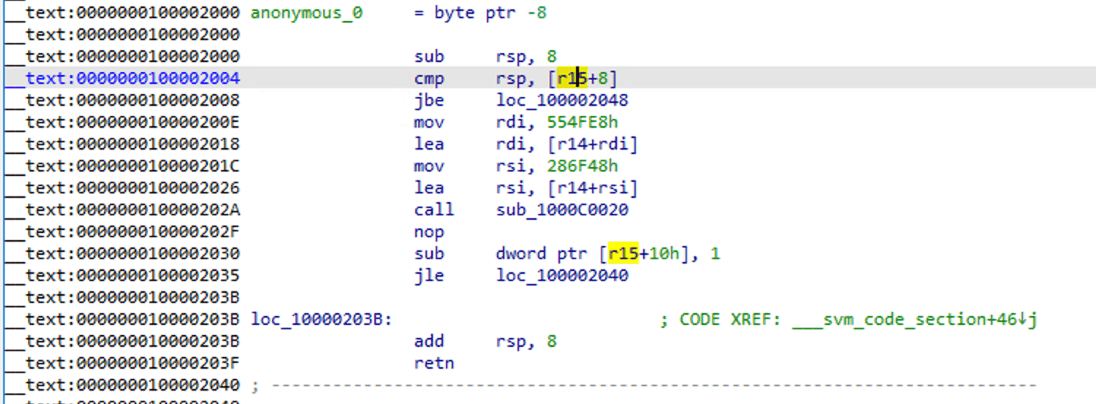
可以看到它已经变成了标准的汇编函数,使用 F5 进行反编译
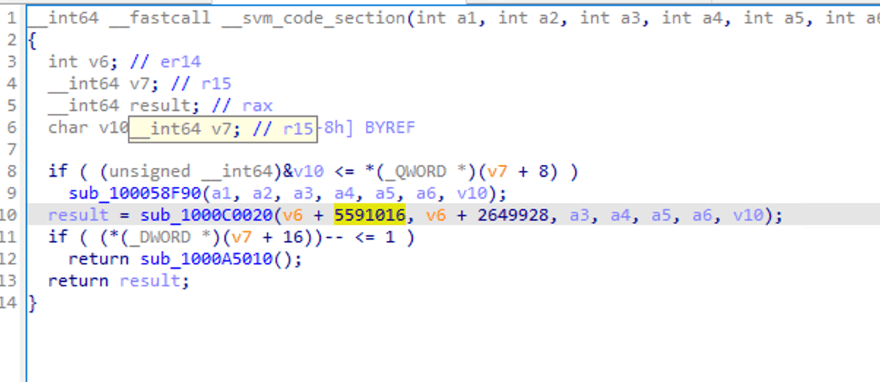
可以看到一些函数调用和传递的参数,但不容易看出逻辑。
当我们双击 sub_1000C0020,看看函数调用内部。IDA 提示分析失败。
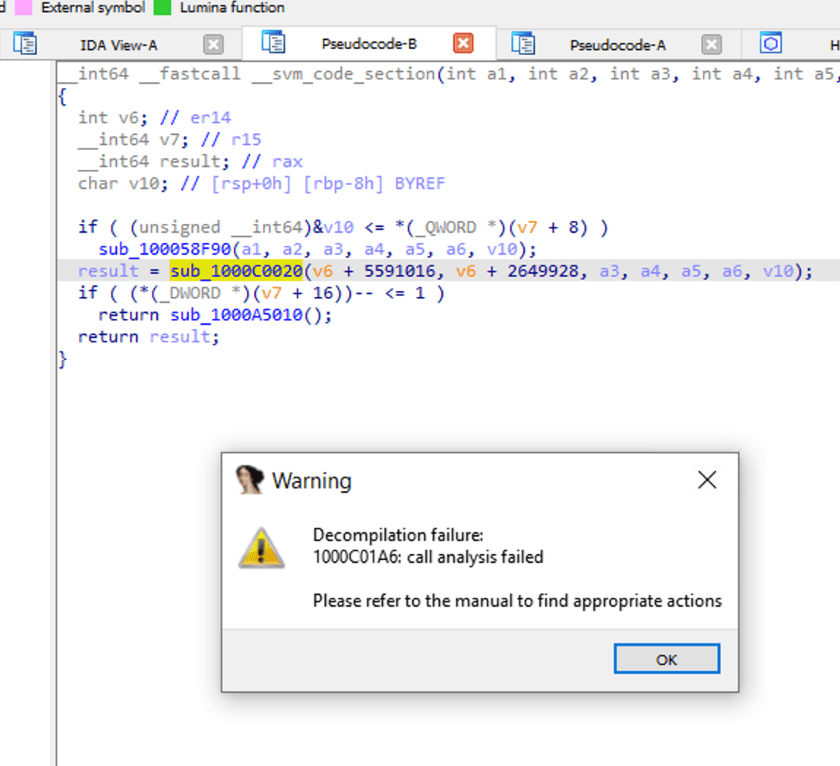
NativeImage 的反编译逻辑
因为 NativeImage 的编译基于 JVM 编译,也可以理解为在二进制代码上包裹了一层 VM 保护。因此,像 IDA 这样的工具在缺乏相应信息和针对性处理措施的情况下无法很好地逆向工程。
然而,无论是字节码还是二进制形式,JVM 执行的一些基本元素必定存在,如类信息、字段信息、函数调用和参数传递。基于这种思路,我开发的分析工具可以实现一定程度的还原效果,并且经过进一步改进,有能力达到更高的还原精度。
使用 NativeImageAnalyzer 进行分析
访问 https://github.com/vlinx-io/NativeImageAnalyzer 下载 NativeImageAnalyzer
执行以下命令进行逆向分析,目前仅分析主类的 Main 函数
native-image-analyzer hello
输出如下
java.io.PrintStream.writeln(java.io.PrintStream@0x554fe8, "Hello World!", rcx)
return
让我们再看看原始代码。
public static void main(String[] args){
System.out.println("Hello World!");
}
现在来看 System.out 的定义。
public static final PrintStream out = null;
可以看到 System 类的 'out' 变量是 PrintStream 类型的变量,而且是静态变量。在编译期间,NativeImage 将该类的一个实例直接编译到名为 Heap 的区域中,二进制代码直接从 Heap 区域获取该实例进行调用。让我们来看还原后的代码。
java.io.PrintStream.writeln(java.io.PrintStream@0x554fe8, "Hello World!", rcx)
return
这里的 java.io.PrintStream@0x554fe8 就是从 Heap 区域读取的 java.io.PrintStream 实例变量,位于内存地址 0x554fe8。
我们再来看下 java.io.PrintStream.writeln 函数的定义
private void writeln(String s) {
......
}
这里可以看到 writeln 函数有一个 String 参数,但在还原后的代码中为什么传递了三个参数?首先 writeln 是类成员方法,隐含了一个 this 变量指向调用者,即传递的第一个参数 java.io.PrintStream@0x554fe8。至于第三个参数 rcx,是因为在分析汇编代码的过程中,确定该函数使用了三个参数进行调用。但通过查看定义,我们知道这个函数实际上只调用了两个参数。这也是该工具未来需要改进的地方。
更复杂的程序
现在我们来分析一个更复杂的程序,例如计算斐波那契数列,代码如下
class Fibonacci {
public static void main(String[] args) {
int count = Integer.parseInt(args[0]);
int n1 = 0, n2 = 1, n3;
System.out.print(n1 + " " + n2);
for (int i = 2; i < count; ++i){
n3 = n1 + n2;
System.out.print(" " + n3);
n1 = n2;
n2 = n3;
}
System.out.println();
}
}
编译并执行
javac Fibonacci.java
native-image -cp . Fibonacci
./fibonacci 10
0 1 1 2 3 5 8 13 21 34
使用 NativeImageAnalyzer 还原后的代码如下
rdi = rdi[0]
ret_0 = java.lang.Integer.parseInt(rdi, 10)
sp_0x44 = ret_0
ret_1 = java.lang.StringConcatHelper.mix(1, 1)
ret_2 = java.lang.StringConcatHelper.mix(ret_1, 0)
sp_0x20 = java.io.PrintStream@0x554fe8
sp_0x18 = Class{[B}_1
tlab_0 = Class{[B}_1
tlab_0.length = ret_2<<ret_2>>32
sp_0x10 = tlab_0
ret_28 = ?java.lang.StringConcatHelper.prepend(tlab_0, " ", ret_2)
ret_29 = java.lang.StringConcatHelper.prepend(ret_28, sp_0x10, 0)
ret_30 = ?java.lang.StringConcatHelper.newString(sp_0x10, ret_29)
java.io.PrintStream.write(sp_0x20, ret_30)
if(sp_0x44>=3)
{
ret_7 = java.lang.StringConcatHelper.mix(1, 1)
tlab_1 = sp_0x18
tlab_1.length = ret_7<<ret_7>>32
sp_0x10 = " "
sp_0x8 = tlab_1
ret_22 = ?java.lang.StringConcatHelper.prepend(tlab_1, " ", ret_7)
ret_23 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_22)
rsi = ret_23
java.io.PrintStream.write(sp_0x20, ret_23)
rdi = 1
rdx = 1
rcx = 3
while(true)
{
if(sp_0x44<=rcx)
{
break
}
else
{
sp_0x34 = rcx
rdi = rdi+rdx
r9 = rdi
sp_0x30 = rdx
sp_0x2c = r9
ret_11 = java.lang.StringConcatHelper.mix(1, r9)
tlab_2 = sp_0x18
tlab_2.length = ret_11<<ret_11>>32
sp_0x8 = tlab_2
ret_17 = ?java.lang.StringConcatHelper.prepend(tlab_2, sp_0x10, ret_11)
ret_18 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_17)
rsi = ret_18
java.io.PrintStream.write(sp_0x20, ret_18)
rcx = sp_0x34+1
rdi = sp_0x30
rdx = sp_0x2c
}
}
}
java.io.PrintStream.newLine(sp_0x20, rsi)
return
将还原后的代码与原始代码进行对比。
rdi = rdi[0]
ret_0 = java.lang.Integer.parseInt(rdi, 10)
sp_0x44 = ret_0
对应的是
int count = Integer.parseInt(args[0]);
rdi 是用于传递函数第一个参数的寄存器,如果是 Windows 则为 rcx。rdi = rdi[0] 对应 args[0],之后调用 java.lang.Integer.parseInt 进行解析获得 int 值,然后将返回值赋给栈变量 sp_0x44。
int n1 = 0, n2 = 1, n3;
System.out.print(n1 + " " + n2);
对应的是
ret_1 = java.lang.StringConcatHelper.mix(1, 1)
ret_2 = java.lang.StringConcatHelper.mix(ret_1, 0)
sp_0x20 = java.io.PrintStream@0x554fe8
sp_0x18 = Class{[B}_1
tlab_0 = Class{[B}_1
tlab_0.length = ret_2<<ret_2>>32
sp_0x10 = tlab_0
ret_28 = ?java.lang.StringConcatHelper.prepend(tlab_0, " ", ret_2)
ret_29 = java.lang.StringConcatHelper.prepend(ret_28, sp_0x10, 0)
ret_30 = ?java.lang.StringConcatHelper.newString(sp_0x10, ret_29)
java.io.PrintStream.write(sp_0x20, ret_30)
在我们的 Java 代码中,简单的字符串拼接操作实际上被转换为三个函数调用:StringConcatHelper.mix、StringConcatHelper.prepend 和 StringConcatHelper.newString。其中,StringConcatHelper.mix 计算拼接后字符串的长度,StringConcatHelper.prepend 将携带具体字符串内容的 byte[] 数组组合在一起,StringConcatHelper.newString 从 byte[] 数组生成新的 String 对象。
在上面的代码中,我们看到两种类型的变量名,sp_0x18 和 tlab_0。以 sp_ 开头的变量表示在栈上分配的变量,而以 tlab_ 开头的变量表示在线程本地分配缓冲区(Thread Local Allocation Buffers)上分配的变量。这只是对这两类变量名来源的解释。在还原后的代码中,这两类变量之间没有区别。关于线程本地分配缓冲区的相关信息,请自行搜索。
这里我们将 tlab_0 赋值为 Class{[B}_1。Class{[B}_1 的含义是 byte[] 类型的一个实例。[B 代表 byte[] 的 Java 描述符,_1 表示它是该类型的第一个变量。如果后续有对应类型的其他变量定义,索引会相应增加,如 Class{[B]}_2、Class{[B]}_3 等。同样的表示方式适用于其他类型,如 Class{java.lang.String}_1、Class{java.util.HashMap}_2 等。
上面代码的逻辑简单来说就是创建一个 byte[] 数组实例并赋值给 tlab0。数组的长度为 ret_2 << ret_2 >> 32。数组长度之所以是 ret_2 << ret_2 >> 32,是因为在计算 String 长度时需要基于编码进行数组长度转换。你可以参考 java.lang.String.java 中的相关代码。接下来,prepend 函数将 0、1 和空格组合到 tlab0 中,然后从 tlab_0 生成新的 String 对象 ret_30,并传递给 java.io.PrintStream.write 函数进行打印输出。实际上,这里 prepend 函数还原的参数不太准确,位置也不正确。这是后续需要进一步改进的地方。
将两行 Java 代码转换为实际执行逻辑后,还是相当复杂的。未来可以在目前还原代码的基础上,通过分析和整合来进行简化。
继续往下看
for (int i = 2; i < count; ++i){
n3 = n1 + n2;
System.out.print(" " + n3);
n1 = n2;
n2 = n3;
}
System.out.println();
对应的是
if(sp_0x44>=3)
{
ret_7 = java.lang.StringConcatHelper.mix(1, 1)
tlab_1 = sp_0x18
tlab_1.length = ret_7<<ret_7>>32
sp_0x10 = " "
sp_0x8 = tlab_1
ret_22 = ?java.lang.StringConcatHelper.prepend(tlab_1, " ", ret_7)
ret_23 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_22)
rsi = ret_23
java.io.PrintStream.write(sp_0x20, ret_23)
rdi = 1
rdx = 1
rcx = 3
while(true)
{
if(sp_0x44<=rcx)
{
break
}
else
{
sp_0x34 = rcx
rdi = rdi+rdx
r9 = rdi
sp_0x30 = rdx
sp_0x2c = r9
ret_11 = java.lang.StringConcatHelper.mix(1, r9)
tlab_2 = sp_0x18
tlab_2.length = ret_11<<ret_11>>32
sp_0x8 = tlab_2
ret_17 = ?java.lang.StringConcatHelper.prepend(tlab_2, sp_0x10, ret_11)
ret_18 = ?java.lang.StringConcatHelper.newString(sp_0x8, ret_17)
rsi = ret_18
java.io.PrintStream.write(sp_0x20, ret_18)
rcx = sp_0x34+1
rdi = sp_0x30
rdx = sp_0x2c
}
}
}
java.io.PrintStream.newLine(sp_0x20, rsi)
return
sp_0x44 是我们输入给程序的参数,即 count。Java 代码中的 for 循环只有在 count >= 3 时才会执行。这里,for 循环被转换回 while 循环,本质上具有相同的语义。在 while 循环之外,程序执行 count=3 时的逻辑。如果 count <= 3,程序完成执行,不会再进入 while 循环。这可能也是 GraalVM 在编译过程中所做的优化。
让我们再看看循环的退出条件。
if(sp_0x44<=rcx)
{
break
}
这对应的是
i < count
同时,rcx 在每次迭代过程中也在累加。
sp_0x34 = rcx
rcx = sp_0x34+1
对应的是
++i
接下来,让我们看看循环体中数字相加的逻辑在还原后的代码中是如何体现的。原始代码如下:
for(......){
......
n3 = n1 + n2;
n1 = n2;
n2 = n3;
......
}
还原后的代码是
while(true){
......
rdi = rdi+rdx -> n3 = n1 + n2
r9 = rdi -> r9 = n3
sp_0x30 = rdx -> sp_0x30 = n2
sp_0x2c = r9 -> sp_0x2c = n3
rdi = sp_0x30 -> n1 = sp_0x30 = n2
rdx = sp_0x2c -> n2 = sp_0x2c = n3
......
}
循环体中的其他代码和之前一样执行字符串拼接和输出操作。还原后的代码基本反映了原始代码的执行逻辑。
仍需进一步改进
目前,该工具能够部分还原程序控制流,实现一定程度的数据流分析和函数名还原。要成为一个完整可用的工具,仍然需要完成以下工作:
更准确的函数名、函数参数和函数返回值还原
准确的对象信息和字段还原
更准确的表达式和对象类型推断
语句整合和简化
关于二进制保护的思考
本项目的目的是探索 NativeImage 逆向工程的可行性。基于目前的成果,对 NativeImage 进行逆向工程是可行的,这也给代码保护带来了更高的挑战。许多开发者认为将软件编译为二进制就可以保证安全,而忽视了对二进制代码的保护。对于用 C/C++ 编写的软件,IDA 等许多工具已经具有优秀的逆向效果,有时甚至比 Java 程序暴露更多信息。我甚至见过一些以二进制形式分发的软件没有去除函数名的符号信息,这等同于裸奔。
任何代码都是由逻辑组成的。只要包含逻辑,就可以通过逆向手段还原其逻辑。唯一的区别在于还原的难度。代码保护就是最大限度地提高这种还原的难度。